SQL- Truy Xuất Dữ Liệu Trong Hệ Sinh Thái Tài Chính Định Lượng (Quant Finance)
SQL- Truy Xuất Dữ Liệu Trong Hệ Sinh Thái Tài Chính Định Lượng (Quant Finance)
Để những mô hình Python, R, và Machine Learning (ML) trong giao dịch định lượng có thể hoạt động, chúng cần dữ liệu sạch, đã được cấu trúc và biến đổi một cách hiệu quả. Ngôn ngữ đảm nhận vai trò nền tảng, lặng lẽ nhưng mang tính quyết định này chính là SQL (Structured Query Language).
SQL không chỉ là một công cụ để truy vấn dữ liệu; nó là một nền tảng tư duy, cho phép các nhà phân tích định lượng xử lý, biến đổi và khám phá các mối quan hệ giữa các bộ dữ liệu khổng lồ (từ giá cổ phiếu, dữ liệu phái sinh, đến tin tức tài chính) ngay tại nguồn, giúp giảm thiểu gánh nặng tính toán cho các công cụ khác như Pandas hay NumPy.
Bài viết này sẽ đi sâu vào năm vai trò cốt lõi của SQL trong một hệ sinh thái Quant hiện đại, chứng minh tại sao nó là kỹ năng bắt buộc phải có cho bất kỳ ai muốn xây dựng sự nghiệp trong lĩnh vực này. Còn nếu bạn tìm kiếm ví dụ thực tế và code snippet khi ứng dụng SQL vào tài chính định lượng, hãy tham khảo blog này:
Nhưng Trước khi bước vào phần đầu tiên, bạn hãy điểm qua các cú pháp SQL dưới đây nếu là lần đầu tiên bạn tiếp xúc với công cụ truy Xuất dữ liệu này:
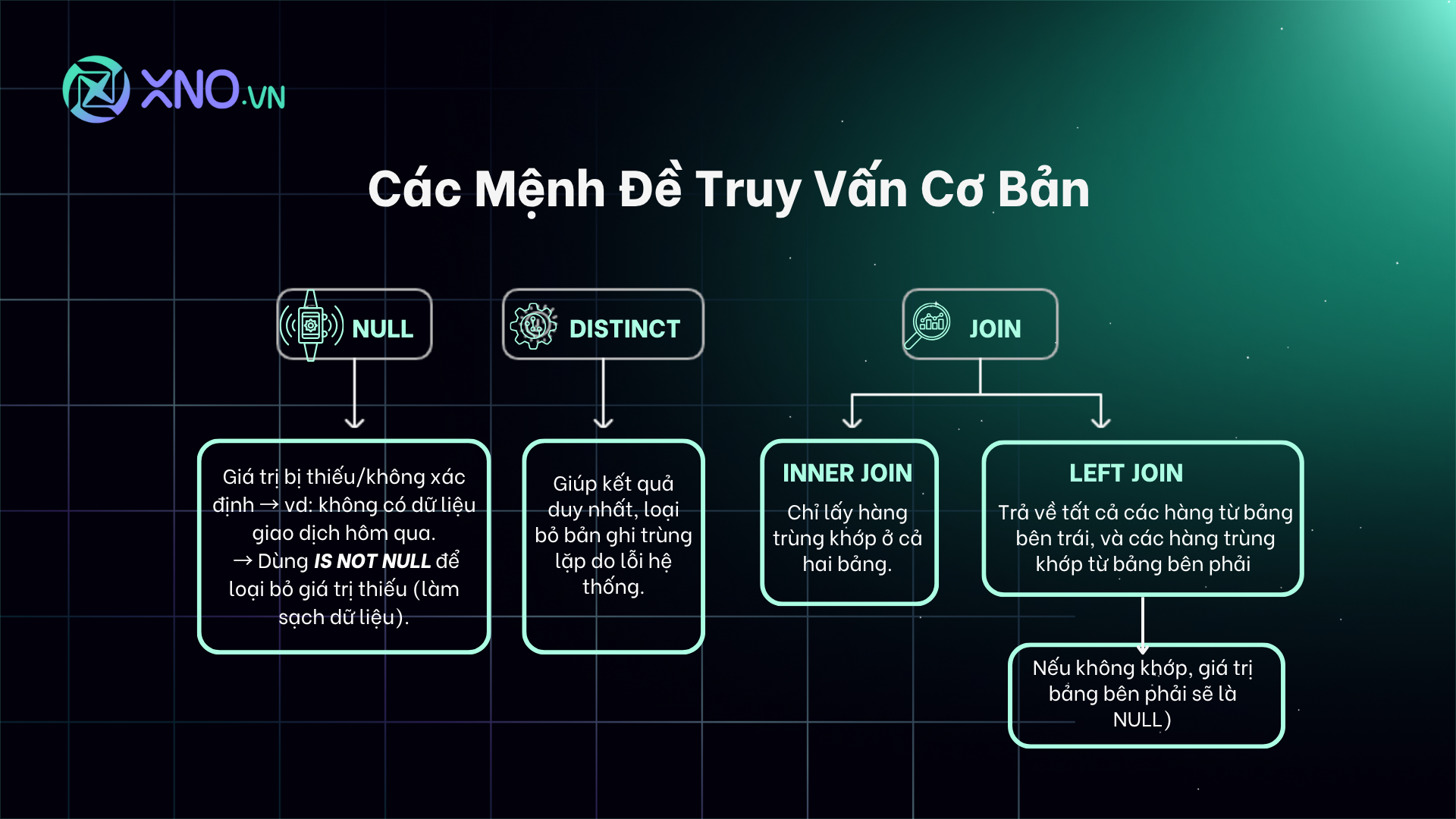
Các Mệnh Đề Truy Vấn Cơ Bản Người Đang Tập Dùng SQL
Trước khi đi sâu vào các kỹ thuật nâng cao, đây là giải thích đơn giản về các thuật ngữ và cú pháp SQL cốt lõi được sử dụng trong bài blog.
Các Mệnh Đề Truy Vấn Cơ Bản.
SELECT, FROM, WHERE, ORDER BY:
SELECT (Chọn gì?): Giống như bạn đang chọn các cột cụ thể (tên cổ phiếu, giá đóng cửa) mà bạn muốn xem từ bảng tính Excel khổng lồ của mình. SELECT close_price, volume.
FROM (Từ đâu?): Xác định tên bảng dữ liệu (ví dụ: bảng prices hoặc quotes) mà bạn đang làm việc.
WHERE (Điều kiện nào?): Bộ lọc của bạn. Cho phép bạn chỉ lấy những hàng đáp ứng một điều kiện nhất định (ví dụ: chỉ lấy dữ liệu sau ngày 01/01/2024).
ORDER BY (Sắp xếp thế nào?): Sắp xếp kết quả theo một cột cụ thể (ví dụ: sắp xếp theo thời gian timestamp để đảm bảo dữ liệu là chuỗi thời gian liên tục).
NULL:
Một giá trị bị thiếu hoặc không xác định. Trong tài chính, nếu giá trị lợi Xuất của ngày hôm qua là NULL, nghĩa là không có dữ liệu giao dịch nào được ghi nhận cho ngày đó.
Mệnh đề IS NOT NULL được dùng để loại bỏ các hàng có giá trị bị thiếu (làm sạch dữ liệu).
DISTINCT:Đảm bảo rằng mọi hàng (hoặc giá trị trong một cột) trong kết quả truy vấn là duy nhất (không có sự trùng lặp). Rất quan trọng để loại bỏ các bản ghi bị nhân đôi do lỗi hệ thống.
JOIN (Kết nối bảng):
Hành động kết hợp dữ liệu từ hai hoặc nhiều bảng khác nhau dựa trên một cột chung (ví dụ: kết nối bảng prices với bảng sentiment_scores bằng cách sử dụng ticker và timestamp là các cột chung).
INNER JOIN: Chỉ trả về các hàng có dữ liệu trùng khớp ở cả hai bảng.
LEFT JOIN: Trả về tất cả các hàng từ bảng bên trái, và các hàng trùng khớp từ bảng bên phải (Nếu không khớp, giá trị bảng bên phải sẽ là NULL).
Các Hàm Tính Toán và Thao Tác Thời Gian Trong SQL
GROUP BY:
Cho phép bạn nhóm các hàng có cùng một giá trị lại với nhau để thực hiện tính toán tổng hợp. Ví dụ: GROUP BY industry để tính lợi nhuận trung bình của mỗi ngành.
DATE_TRUNC & EXTRACT:
Các hàm để thao tác với cột thời gian (timestamp).
DATE_TRUNC('month', ...): Cắt bớt (truncate) thời gian về đầu tháng, giúp bạn dễ dàng nhóm và tính tổng lợi nhuận theo tháng.
EXTRACT(YEAR FROM ...): Trích xuất một phần cụ thể của ngày giờ (ví dụ: chỉ lấy năm) để bạn có thể lọc hoặc nhóm dữ liệu.
Các Hàm Cửa Sổ (Window Functions - Khả năng tính Toán mạnh trong SQL)
Các hàm cửa sổ là yếu tố làm nên sức mạnh của SQL trong Quant Finance. Chúng thực hiện tính toán trên một tập hợp các hàng liên quan (cửa sổ) mà không làm giảm số lượng hàng trong kết quả.
OVER (PARTITION BY ...):
Định nghĩa "cửa sổ" tính toán. PARTITION BY cho phép bạn chia dữ liệu thành các nhóm độc lập (ví dụ: tính toán MA cho từng ticker riêng biệt).
AVG() OVER (...): Tính toán Trung bình Động (Moving Average). Nó tính giá trị trung bình trên một "cửa sổ trượt" (ví dụ: 20 ngày gần nhất) và điền kết quả vào từng hàng.
LAG():
Một hàm cửa sổ cho phép bạn truy cập giá trị của một hàng trước đó trong cùng một tập dữ liệu.
Ứng dụng: Rất quan trọng để tính Lợi suất hàng ngày, vì bạn cần giá đóng cửa của ngày hôm qua (LAG(close_price, 1)) để so sánh với giá đóng cửa hôm nay.
PERCENTILE_CONT:
Tính toán phân vị (percentile) của một tập dữ liệu (ví dụ: phân vị thứ 5 - P5).
Ứng dụng: Giúp ước tính Rủi ro đuôi (Tail Risk) hoặc Value at Risk (VaR), bằng cách tìm ra mức lỗ tồi tệ nhất trong 5% các trường hợp.
ROLLUP, CUBE, GROUPING SETS:
Các cú pháp nâng cao của GROUP BY được dùng cho phân tích đa chiều. Chúng tự động tạo ra các hàng tổng cộng (subtotals) ở nhiều cấp độ phân cấp (ví dụ: tổng lợi nhuận theo Ticker, sau đó là tổng lợi nhuận theo Ngành, và cuối cùng là Tổng lợi nhuận toàn bộ).
Đọc sơ qua về định nghĩa các hàm này sẽ giúp bạn hiểu xử lý nội dung của blog tốt hơn. Tiếp theo, cùng XNO tìm hiểu ứng dụng của SQL trong tài chính định lượng nhé.
I. Truy Xuất và Tiền Xử Lý Dữ Liệu Trong SQL
Giai đoạn đầu tiên và quan trọng nhất của mọi dự án Quant là lấy dữ liệu. Dữ liệu tài chính thường được lưu trữ trong các cơ sở dữ liệu quan hệ (PostgreSQL, MySQL, SQL Server) hoặc kho dữ liệu lớn (Snowflake, BigQuery). SQL là ngôn ngữ duy nhất có thể tương tác hiệu quả với các nguồn này.
Lấy dữ liệu giá cổ phiếu, phái sinh, tiền mã hóa
Một trong những ứng dụng phổ biến và cần thiết nhất của SQL là khả năng truy xuất dữ liệu giá lịch sử của các tài sản như cổ phiếu, phái sinh hay tiền mã hóa từ các bảng dữ liệu lớn (thường là bảng prices hoặc quotes). Các nhà phân tích Quant cần dùng lệnh SELECT để chỉ lấy các cột cần thiết (ví dụ: ticker, timestamp, close_price, volume), kết hợp với mệnh đề WHERE để lọc theo các điều kiện cụ thể như phạm vi ngày tháng, loại tài sản, hoặc sàn giao dịch, và sử dụng ORDER BY để sắp xếp theo thứ tự thời gian, đảm bảo chuỗi thời gian là liền mạch và có thể tái tạo được, điều này cực kỳ quan trọng cho các thử nghiệm backtesting và kiểm tra tính nhất quán của dữ liệu. Nếu không có các mệnh đề lọc và sắp xếp chính xác này, việc truyền toàn bộ tập dữ liệu thô (có thể lên đến hàng terabyte) sang Python để xử lý sẽ gây lãng phí tài nguyên và làm chậm quá trình phân tích một cách đáng kể.
Làm sạch dữ liệu (remove nulls, duplicates)
Trong các hệ thống giao dịch tốc độ cao, dữ liệu thường bị thiếu (NULL values) do lỗi truyền tải hoặc không có giao dịch trong phiên. SQL cho phép thực hiện tiền xử lý dữ liệu cơ bản ngay tại tầng cơ sở dữ liệu để loại bỏ các điểm dữ liệu không hợp lệ hoặc không cần thiết trước khi chúng được tải vào bộ nhớ (ví dụ: Pandas DataFrame). Kỹ thuật này bao gồm việc sử dụng mệnh đề WHERE column IS NOT NULL để loại bỏ các hàng bị thiếu giá trị, sử dụng DISTINCT để đảm bảo không có các hàng dữ liệu trùng lặp (thường xảy ra do ghi nhận nhiều lần), và tận dụng GROUP BY kết hợp với các hàm tổng hợp như AVG hoặc MAX để xử lý các điểm bất thường, giúp tạo ra một tập dữ liệu sạch, nhất quán, giảm thiểu rủi ro lỗi trong các bước tính toán chỉ báo và mô hình hóa phức tạp sau này.
Trích xuất dữ liệu theo thời gian
Phân tích Quant luôn gắn liền với thời gian, và SQL cung cấp các hàm mạnh mẽ để thao tác và trích xuất thông tin từ trường thời gian (timestamp). Các nhà phân tích thường sử dụng các hàm như DATE_TRUNC('month', timestamp_column) hoặc EXTRACT(YEAR FROM timestamp_column) để nhóm dữ liệu giao dịch theo các khung thời gian lớn hơn (ví dụ: tính lợi suất theo tuần, tháng, hoặc quý), một bước quan trọng trong kỹ thuật Resampling mà nếu thực hiện trong Python/Pandas có thể tốn kém hơn về mặt hiệu suất khi xử lý dữ liệu lớn. Khả năng lọc dữ liệu theo thời gian (ví dụ: chỉ lấy dữ liệu sau 4 giờ chiều cho chiến lược giao dịch cuối ngày) giúp Quant chỉ truy xuất chính xác những gì cần thiết cho phân tích, tối ưu hóa quá trình tải và xử lý dữ liệu.
II. Dùng SQL đề Biến đổi Dữ liệu Sử dụng cho Mô hình Giao dịch
Giai đoạn này là nơi SQL thực sự tỏa sáng, cho phép tạo ra các chỉ báo và đặc trưng (features) quan trọng mà không cần dựa vào Python, đặc biệt hữu ích khi xử lý dữ liệu Big Data.
Tính toán trung bình động, lợi suất
Việc tính toán các chỉ báo kỹ thuật cơ bản như Đường Trung bình Động (Moving Averages - MA) hay Lợi suất (Returns) là bước không thể thiếu trong mọi chiến lược Quant. SQL giải quyết nhu cầu này một cách thanh lịch và hiệu quả thông qua Window Functions. Ví dụ, để tính MA 20 ngày, Quant sẽ sử dụng cấu trúc AVG(close_price) OVER (ORDER BY timestamp ROWS BETWEEN 19 PRECEDING AND CURRENT ROW), cho phép tính toán giá trị trung bình trượt một cách chính xác trên mỗi hàng dữ liệu mà không cần self-join phức tạp. Tương tự, LAG(close_price, 1) OVER (ORDER BY timestamp) được sử dụng để lấy giá đóng cửa của ngày trước đó, từ đó dễ dàng tính toán lợi suất hàng ngày ((price / LAG(price)) - 1), đảm bảo tính toán các đặc trưng (features) cốt lõi này được thực hiện nhanh chóng, song song và tối ưu ngay tại tầng cơ sở dữ liệu.
Tạo cột phân loại (labels)
Trong Machine Learning, mô hình cần các cột mục tiêu (labels) đã được phân loại để học. SQL cung cấp các công cụ lý tưởng để tạo ra các nhãn này dựa trên các điều kiện kinh doanh hoặc giao dịch cụ thể. Các nhà phân tích thường sử dụng các câu lệnh CASE WHEN ... THEN ... ELSE ... END hoặc hàm IF() để gán nhãn cho từng hàng dữ liệu. Ví dụ, họ có thể tạo ra nhãn 'BUY' nếu lợi suất ngày mai lớn hơn một ngưỡng (ví dụ: 1%) và nhãn 'SELL' nếu lợi suất nhỏ hơn ngưỡng âm (-1%), hoặc dùng CAST() để chuyển đổi các cột số thành kiểu dữ liệu phù hợp (Boolean, Integer) cho các mô hình phân loại. Khả năng tạo nhãn chính xác trong SQL đảm bảo rằng dữ liệu huấn luyện (training data) của mô hình ML đã được chuẩn bị hoàn hảo trước khi Python bắt đầu xử lý.
Kết hợp nhiều nguồn dữ liệu
Các chiến lược giao dịch tinh vi thường đòi hỏi sự kết hợp của nhiều loại dữ liệu khác nhau (giá, khối lượng giao dịch, dữ liệu kinh tế vĩ mô, và điểm số cảm xúc từ tin tức). SQL sử dụng các phép JOIN để hợp nhất các nguồn dữ liệu này một cách logic và hiệu quả. Ví dụ, một nhà phân tích có thể dùng INNER JOIN để kết hợp bảng stock_prices với bảng sentiment_scores chỉ dựa trên cột timestamp và ticker, đảm bảo rằng chỉ những ngày có đầy đủ cả dữ liệu giá và dữ liệu tin tức mới được đưa vào phân tích. Sử dụng LEFT JOIN cho phép Quant giữ lại tất cả các hàng dữ liệu giá ngay cả khi không có dữ liệu tin tức tương ứng, sau đó xử lý các giá trị NULL này trong Python. Khả năng này là cốt lõi để xây dựng các đặc trưng (features) phức tạp dựa trên sự kết hợp đa nguồn.
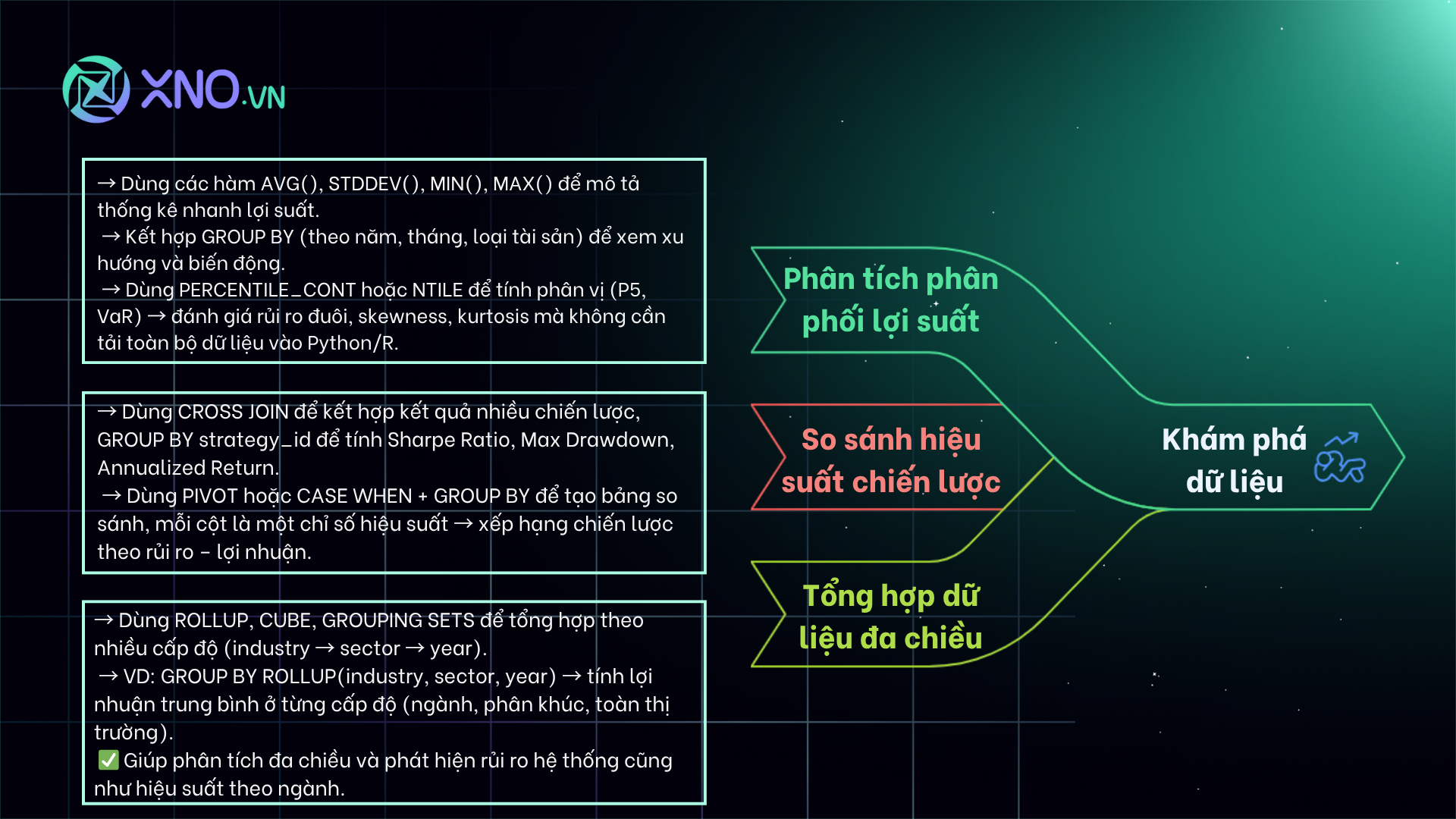
III. Exploratory Data Analysis (EDA) sử dụng SQL
Trước khi xây dựng mô hình, Quant cần khám phá dữ liệu để hiểu các đặc tính thống kê và xác định các điểm bất thường. SQL là một công cụ mạnh mẽ cho EDA, đặc biệt khi cần tổng hợp dữ liệu quy mô lớn.
Phân tích phân phối lợi suất
Để đánh giá rủi ro và hiệu suất của một tài sản hoặc chiến lược, các nhà phân tích Quant cần hiểu về phân phối lợi suất. SQL giúp thực hiện các tính toán thống kê mô tả nhanh chóng như AVG(), STDDEV(), MIN(), MAX() lợi suất, sử dụng mệnh đề GROUP BY để nhóm các kết quả này theo các yếu tố phân loại như năm, tháng, hoặc loại tài sản (ngành, vốn hóa thị trường). Hơn nữa, Quant có thể tính toán các giá trị phân vị (percentiles) (ví dụ: phân vị thứ 5 để ước tính rủi ro đuôi, thường là một phần của VaR) bằng các hàm như PERCENTILE_CONT hoặc NTILE, cho phép họ nhanh chóng xác định các đặc tính của phân phối lợi suất như sự lệch (skewness) và độ nhọn (kurtosis) của thị trường mà không cần phải tải toàn bộ dữ liệu vào môi trường Python/R.
So sánh hiệu suất các chiến lược
Trong môi trường backtesting, các Quant thường chạy đồng thời hàng chục, thậm chí hàng trăm chiến lược khác nhau. SQL giúp so sánh hiệu suất của chúng một cách hiệu quả. Bằng cách sử dụng CROSS JOIN để kết hợp kết quả của nhiều chiến lược (mỗi chiến lược có thể nằm trong một bảng riêng), sau đó sử dụng GROUP BY strategy_id và các hàm tổng hợp để tính toán các chỉ số hiệu suất như Sharpe Ratio (tỷ lệ lợi nhuận so với rủi ro), Maximum Drawdown (mức sụt giảm tối đa), và Annualized Return. Các kỹ thuật như PIVOT (hoặc hàm CASE WHEN với GROUP BY) cho phép Quant chuyển đổi dữ liệu từ định dạng hàng sang định dạng cột, tạo ra một bảng tóm tắt trực quan, nơi mỗi cột là một chỉ số hiệu suất của một chiến lược, giúp dễ dàng so sánh và xếp hạng chiến lược nào là tốt nhất dựa trên các tiêu chí rủi ro-lợi nhuận khác nhau.
Tổng hợp dữ liệu theo ngành, tài sản, khoảng thời gian
Khả năng tổng hợp dữ liệu theo nhiều cấp độ phân cấp là chìa khóa để phân tích đa chiều (Multi-dimensional Analysis). SQL cung cấp các cú pháp mở rộng của GROUP BY như ROLLUP, CUBE, và GROUPING SETS để giải quyết việc này. Ví dụ, một nhà phân tích có thể sử dụng GROUP BY ROLLUP(industry, sector, year) để tính toán lợi nhuận trung bình không chỉ ở cấp độ năm-ngành-phân khúc, mà còn ở cấp độ tổng ngành, tổng phân khúc, và tổng cộng toàn bộ. Kỹ thuật này cho phép Quant nhanh chóng tạo ra các báo cáo phân tích hiệu suất ở mọi cấp độ chi tiết, từ vi mô (từng tài sản) đến vĩ mô (tổng thị trường), điều này đặc biệt quan trọng khi xác định các yếu tố rủi ro hệ thống (systemic risk) và hiệu suất theo ngành.
IV. Backtesting và Kiểm tra Kết quả với SQL
Giai đoạn quan trọng nhất trong phát triển chiến lược là backtesting và theo dõi hiệu suất thực tế. SQL là công cụ lý tưởng để lưu trữ và truy vấn kết quả.
Lưu trữ kết quả backtest
Để đảm bảo tính minh bạch, khả năng kiểm toán và tái tạo, mọi kết quả backtest (hay còn gọi là mô phỏng giao dịch) cần được lưu trữ có cấu trúc. SQL được sử dụng để định nghĩa và tạo các bảng chuyên dụng (ví dụ: bảng backtest_results) để lưu trữ các chỉ số quan trọng như Lợi nhuận gộp (PnL), Đường cong vốn chủ sở hữu (Equity Curve), Maximum Drawdown, Sharpe Ratio, và các tham số đầu vào của chiến lược (strategy_params). Cấu trúc bảng phải được thiết kế tối ưu với các chỉ mục (indexes) trên các cột quan trọng (như strategy_id và date) để đảm bảo việc truy vấn và phân tích hiệu suất sau này là cực kỳ nhanh chóng, cho phép Quant dễ dàng theo dõi hiệu suất lịch sử và thay đổi theo thời gian của chiến lược, một phần không thể thiếu của quá trình kiểm soát chất lượng.
Truy vấn hiệu suất theo từng phiên giao dịch
Theo dõi hiệu suất chi tiết theo từng ngày hoặc từng phiên giao dịch là cần thiết để xác định các yếu tố gây ra lỗ hoặc lãi. SQL cho phép Quant thực hiện các truy vấn sâu để tính toán các số liệu hiệu suất tích lũy. Ví dụ, họ có thể dùng SUM(profit) OVER (ORDER BY date) để tính toán lợi nhuận tích lũy (Cumulative PnL), từ đó xây dựng đường cong vốn chủ sở hữu. Họ cũng có thể dùng các hàm cửa sổ kết hợp với MAX để tính toán drawdown tối đa tại bất kỳ thời điểm nào. Khả năng truy vấn hiệu suất tại bất kỳ điểm thời gian nào (ví dụ: hiệu suất trong tháng 3 của năm 2024) chỉ bằng một câu lệnh WHERE đơn giản giúp cho việc phân tích và gỡ lỗi (debugging) các chiến lược backtested trở nên hiệu quả và nhanh chóng hơn nhiều so với việc tính toán lại trong Python.
So sánh nhiều chiến lược trong cùng điều kiện
Trong các công ty Quant lớn, việc so sánh hiệu suất giữa hàng trăm chiến lược (thuộc các nhóm chiến lược khác nhau như Mean Reversion, Momentum, hay Arbitrage) là một tác vụ thường xuyên. SQL giúp thực hiện điều này bằng cách JOIN nhiều bảng kết quả backtest hoặc sử dụng các mệnh đề GROUP BY strategy_type để tổng hợp kết quả. Sau đó, các nhà phân tích có thể tính toán tương quan hiệu suất (performance correlation) giữa các chiến lược, điều này cực kỳ quan trọng để xây dựng một danh mục chiến lược đa dạng và giảm thiểu rủi ro hệ thống (Systemic Risk). Khả năng truy vấn và so sánh hàng loạt này giúp Quant nhanh chóng loại bỏ các chiến lược kém hiệu quả hoặc các chiến lược có hiệu suất tương tự nhau, từ đó tối ưu hóa việc phân bổ vốn cho các chiến lược có lợi nhuận và ít tương quan nhất.
V. Tự động hóa SQL để kết hợp với techstack của Quant
Trong một hệ sinh thái Quant hiện đại, SQL là cầu nối giữa dữ liệu và các công cụ phân tích cao cấp hơn, hỗ trợ tự động hóa toàn bộ quy trình.
Kết nối SQL với Python (Pandas, SQLAlchemy)
SQL là ngôn ngữ chính được sử dụng để tạo ra các truy vấn được gọi từ các môi trường phân tích Python. Các thư viện Python như Pandas (với pd.read_sql_query) và SQLAlchemy được sử dụng để thiết lập kết nối và tự động hóa truy vấn dữ liệu. Điều này cho phép Quant viết các truy vấn SQL tối ưu để tính toán các đặc trưng (features) phức tạp (ví dụ: MACD, RSI) ở tầng cơ sở dữ liệu và chỉ tải các kết quả cuối cùng vào bộ nhớ Python. Phương pháp này giảm thiểu nhu cầu tính toán nặng nề trong Python/Pandas, đặc biệt khi xử lý dữ liệu tick-by-tick khổng lồ, và giúp cho toàn bộ quy trình (data loading, preprocessing, feature generation) trở nên hiệu quả và có khả năng mở rộng (scalable) cao hơn.
Tích hợp với dashboards (Streamlit, Metabase)
Các dashboard trực quan hóa là cách hiệu quả nhất để theo dõi hiệu suất chiến lược theo thời gian thực. SQL được sử dụng làm nguồn dữ liệu trực tiếp cho các công cụ dashboard như Metabase, Tableau, hoặc các ứng dụng Python tương tác như Streamlit. Thay vì phải viết code Python để tính toán lại các số liệu hiệu suất mỗi lần dashboard được tải, các công cụ này chỉ cần thực thi các câu lệnh SELECT SUM(PnL) FROM daily_results WHERE date > '...' đã được tối ưu hóa. Điều này đảm bảo rằng dashboard hiển thị dữ liệu mới nhất, chính xác, và cực kỳ nhanh chóng, cho phép các nhà quản lý quỹ và Quant theo dõi các chỉ số rủi ro và lợi nhuận quan trọng mà không bị trễ thời gian.
Thiết lập cron jobs để cập nhật dữ liệu hàng ngày
Quy trình Quant đòi hỏi dữ liệu được cập nhật liên tục và chính xác. SQL là một phần không thể thiếu trong các tác vụ tự động hóa dữ liệu (ETL/ELT) được lên lịch. Các câu lệnh SQL được gói gọn trong các kịch bản (scripts) hoặc thủ tục lưu trữ (stored procedures) và được lên lịch chạy tự động hàng đêm thông qua các công cụ như cron jobs (trên Linux) hoặc Apache Airflow. Mục đích là để nhập (INSERT) dữ liệu giá mới nhất, tính toán lại các chỉ báo kỹ thuật (MA, Volatility) và cập nhật các bảng tổng hợp theo ngày. Việc hiểu rõ cấu trúc bảng và viết các truy vấn tối ưu (ví dụ: sử dụng UPSERT thay vì DELETE/INSERT để cập nhật hiệu quả) là cần thiết để duy trì tính toàn vẹn của dữ liệu chuỗi thời gian khổng lồ mà các mô hình ML và backtester phụ thuộc vào.
Kết Luận: SQL là Cốt Lõi, Python là Lớp Bề Mặt
Trong lĩnh vực Tài chính Định lượng, nơi hiệu suất và độ chính xác của dữ liệu là tối quan trọng, SQL đóng vai trò là kiến trúc sư nền tảng. Nó không phải là một công cụ phân tích bóng bẩy như Python hay thư viện Machine Learning, mà là xương sống chịu tải của toàn bộ quy trình.
Từ việc đảm bảo dữ liệu thô được truy xuất và làm sạch, tạo ra các đặc trưng phức tạp bằng Window Functions, đến việc lưu trữ và truy vấn kết quả backtesting, SQL tối ưu hóa mọi bước trong quy trình xử lý dữ liệu lớn. Bất kỳ chuyên gia Quant nào muốn làm việc với dữ liệu giao dịch quy mô lớn đều phải thành thạo SQL để viết các truy vấn hiệu quả, có khả năng mở rộng, và đảm bảo mô hình Machine Learning của họ được xây dựng trên một nền tảng dữ liệu vững chắc.
Trong quá trình học tập, nếu bạn có thắc mắc hoặc khó khăn gì, hãy up câu hỏi lên group Quant & AI Việt Nam - Đầu tư định lượng. Các thành viên và XNO sẽ có mặt để hổ trợ quá trình học tập của bạn.
Ngoài ra, hàng thángcác chuyên gia sẽ chủ trì 1 workshop offline. Mọi kiến thức và video của workshop đều được chia sẻ công khai trên group, vì vậy, hãy nhớ theo dõi các hoạt động của group để cập nhật các thông tin và sự kiện hữu ích sớm nhất nhé.