Bài blog này là một hướng dẫn thực hành xuyên suốt hành trình xây dựng một mô hình giao dịch đơn giản dựa trên chiến lượcmomentum của Nhà đầu tư B (giả định).
Nhà đầu tư B sử dụng ba bảng dữ liệu chính:
prices: Dữ liệu giá lịch sử của cổ phiếu (ticker, timestamp, close_price).
index_performance: Dữ liệu về chỉ số thị trường chung (timestamp, VNINDEX_return).
news_sentiment: Dữ liệu cảm xúc thị trường (timestamp, sentiment_score).
Mục tiêu của B là: Tạo ra một tập dữ liệu sạch, giàu đặc trưng (features) và có nhãn mục tiêu (labels) sẵn sàng cho mô hình học máy (ML).
I. Làm Sạch Dữ Liệu và Tính Lợi Suất Cơ Bản
Kịch bản 1: Chuẩn bị Dữ liệu Gốc (Bảng prices)
Nhà đầu tư B quyết định tập trung vào cổ phiếu HPG (Hòa Phát). B cần truy xuất tất cả dữ liệu giá đóng cửa của HPG trong năm 2024 và đảm bảo rằng không có ngày nào bị thiếu giá (NULL) để việc tính toán tiếp theo không bị lỗi.
Kịch bản 2: Tạo Đặc Trưng (Feature) Lợi Suất
Để đo lường tốc độ thay đổi của HPG, B cần tính Lợi suất Hàng ngày (Daily Return). B sử dụng hàm cửa sổ LAG() để so sánh giá đóng cửa hôm nay với giá đóng cửa ngày hôm trước, một cách tính toán an toàn và hiệu quả ngay tại cơ sở dữ liệu.
II. Xây Dựng Đặc Trưng Kỹ Thuật (Feature Engineering)
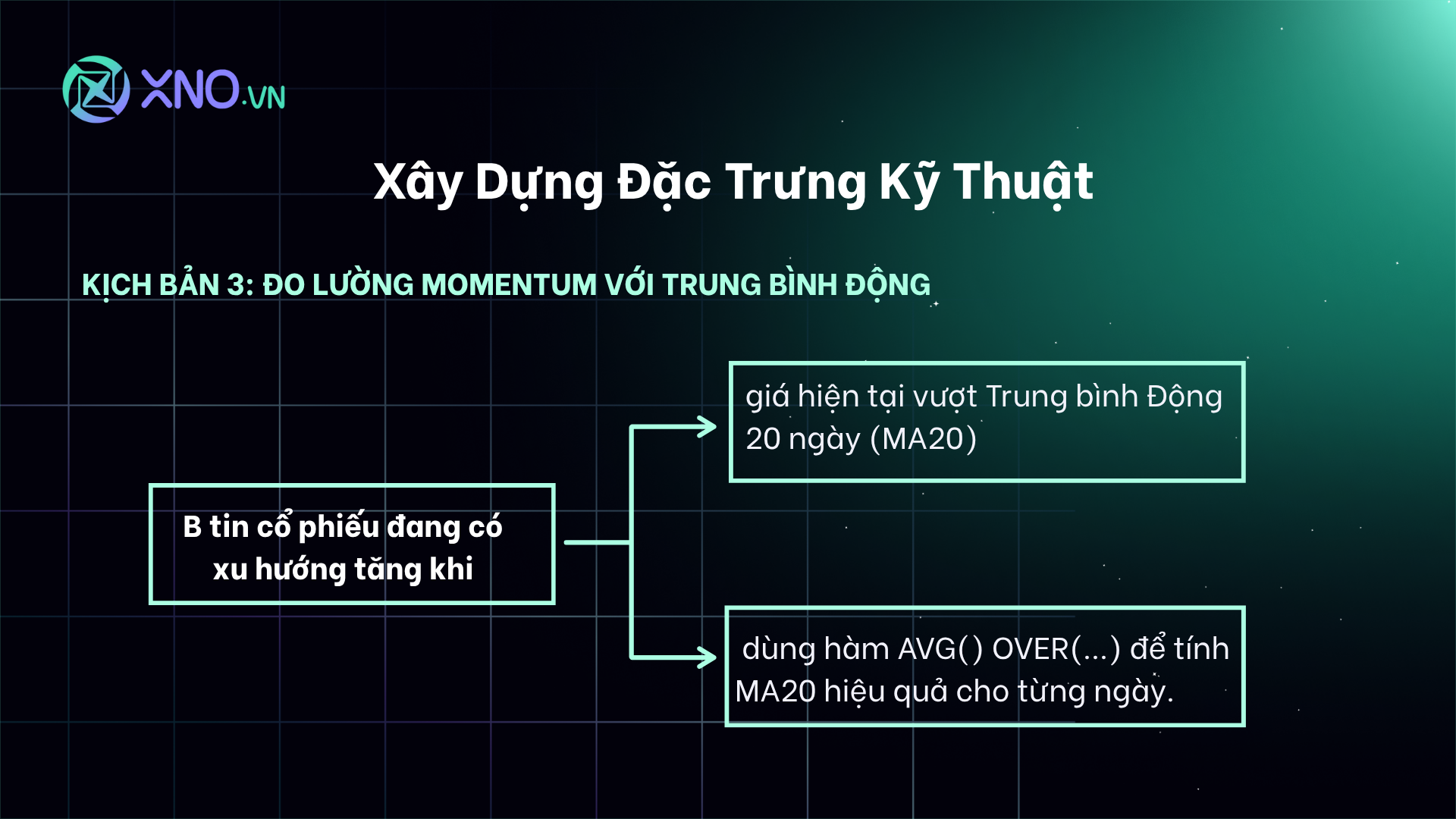
Kịch bản 3: Đo lường Momentum với Trung Bình Động
Nhà đầu tư B tin rằng cổ phiếu đang trong xu hướng tăng nếu giá hiện tại cao hơn Trung bình Động 20 ngày (MA20). B sử dụng hàm cửa sổ AVG() OVER (...) để tính MA20 một cách hiệu quả cho từng ngày.
Kịch bản 4: Đo lường Rủi Ro với Độ Biến Động
Để kiểm soát rủi ro, B cần biết độ biến động của HPG trong 10 ngày gần nhất. B sử dụng hàm STDDEV() trên cột daily_return (được tính ở Kịch bản 2) trong một cửa sổ trượt 10 ngày.
III. Tạo Nhãn Mục Tiêu (Target Label) Một Cách An Toàn
Kịch bản 5: Tránh Nhìn Trộm Tương Lai (Look-ahead Bias)
Nhà đầu tư B muốn mô hình dự đoán liệu HPG sẽ tăng giá hơn 1.5% vào ngày mai (T+1) hay không. Để tránh sử dụng thông tin tương lai, B bắt buộc phải sử dụng hàm LEAD() để dịch chuyển cột lợi suất sang ngày hiện tại.
B sẽ tạo ra một nhãn Phân loại (BUY, SELL, HOLD) cho mô hình.
IV. Tích Hợp Dữ Liệu Đa Nguồn (Joining)
Kịch bản 6: Thêm Bối Cảnh Thị Trường Chung
Nhà đầu tư B nhận ra rằng việc HPG tăng hay giảm thường phụ thuộc vào thị trường chung (VNIndex). B muốn kết hợp lợi suất 5 ngày của VNIndex (từ bảng index_performance) với tất cả các đặc trưng của HPG. B sử dụng LEFT JOIN để đảm bảo không mất đi dữ liệu HPG ngay cả khi dữ liệu VNIndex bị thiếu một ngày.
V. Kết Nối SQL và Python (Bước cuối cùng)
Kịch bản 7: Đưa Dữ Liệu Sạch vào Pandas để Huấn Luyện ML
Sau khi đã hoàn thành các bước tiền xử lý, tạo đặc trưng và nhãn mục tiêu trong SQL, Nhà đầu tư B thực thi câu lệnh SQL cuối cùng để tải tập dữ liệu hoàn chỉnh (X và Y) vào Pandas DataFrame.
VI. Kết Luận: Tối Ưu Hóa Quy Trình Định Lượng Với SQL
Chúng ta vừa quan sát cách SQL giúp nhà đầu tư B tối ưu quá trình tạo đặc trưng (Feature Engineering) quy mô lớn. Bằng cách tận dụng các Hàm Cửa Sổ (Window Functions) như LAG(), LEAD(), và AVG() OVER (...), B đã chuyển gánh nặng tính toán từ Python sang Database, giúp quá trình tiền xử lý trở nên nhanh và hiệu quả hơn.
Quan trọng nhất, B đã học cách bảo vệ mô hình khỏi "nhìn trộm tương lai" (look-ahead bias) bằng cách dùng LEAD() để định vị nhãn mục tiêu T+1 một cách chính xác. Bằng cách kết hợp dữ liệu đa nguồn bằng JOIN và chuẩn hóa tập dữ liệu cuối cùng là bước cuối cùng, B đã có một mảng NumPy sạch sẽ, sẵn sàng cho việc huấn luyện mô hình ML.
Đây chỉ là một trong hằng hà sa số các cách ứng dụng SQL trong giao dịch định lượng, bạn hãy tham khảo và sử dụng thử các đoạn code phía trên, và nếu có thắc mắc hoặc khó khăn gì, hãy up câu hỏi lên group Quant & AI Việt Nam - Đầu tư định lượng. Các thành viên và XNO sẽ có mặt để hổ trợ quá trình học tập của bạn.
Ngoài ra, hàng thángcác chuyên gia sẽ chủ trì 1 workshop offline . Mọi kiến thức và video của workshop đều được chia sẻ công khai trên group, vì vậy, hãy nhớ theo dõi các hoạt động của group để cập nhật các thông tin và sự kiện hữu ích sớm nhất nhé.