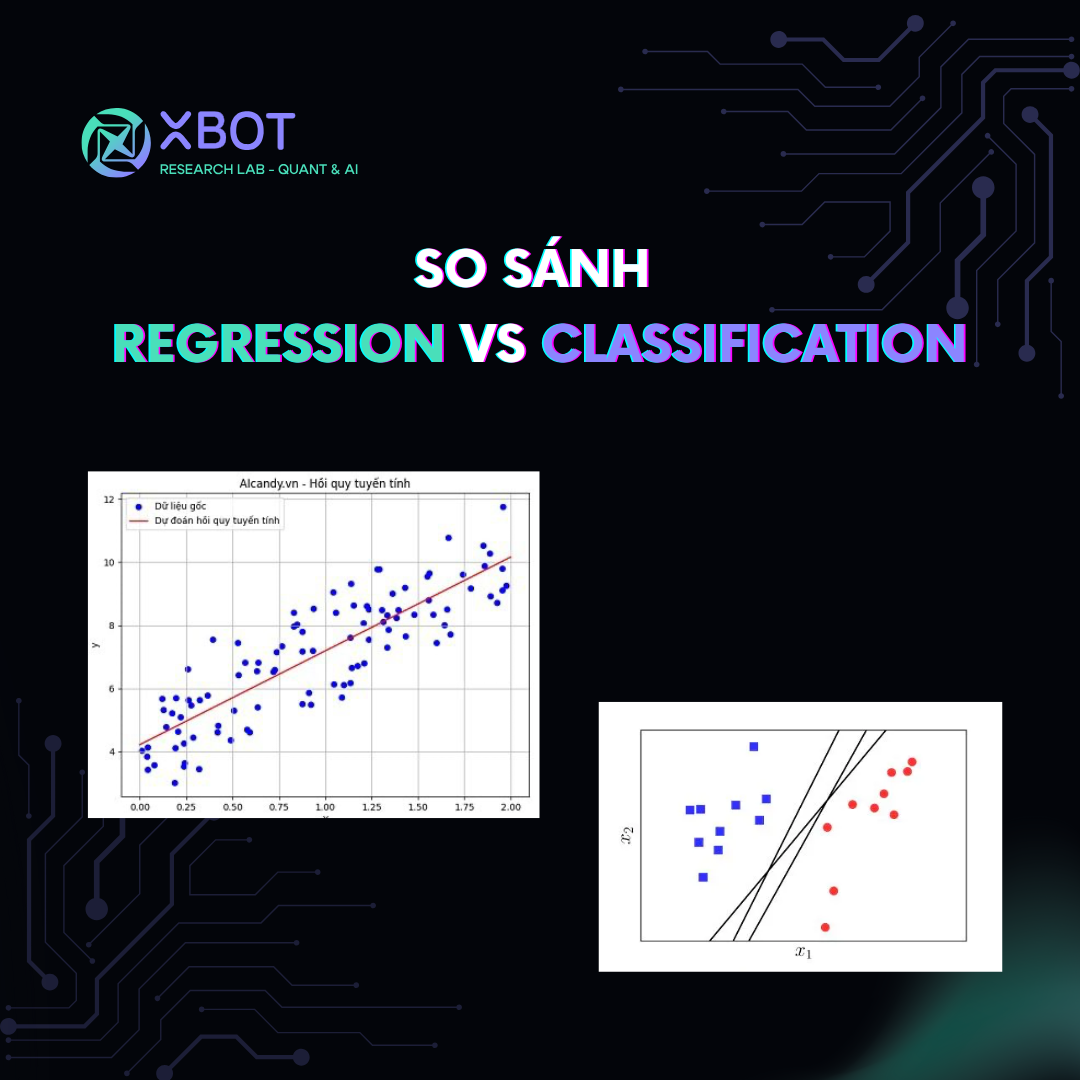
Regression vs Classification – ứng dụng trong thị trường tài chính
Regression vs Classification – ứng dụng trong thị trường tài chính
Machine learning (học máy) ngày càng được ứng dụng sâu rộng trong lĩnh vực tài chính. Hai kỹ thuật cơ bản và phổ biến nhất trong học máy là Regression (hồi quy) và Classification (phân loại). Việc hiểu rõ sự khác nhau giữa hai phương pháp này sẽ giúp bạn lựa chọn mô hình phù hợp cho các bài toán như: dự đoán giá cổ phiếu, đánh giá rủi ro tín dụng, hay phát hiện gian lận tài chính.
2 Khái niệm cơ bản
1. Regression – Hồi quy
Regression là một kỹ thuật học có giám sát (supervised learning) dùng để dự đoán giá trị liên tục của một biến phụ thuộc (output) dựa trên các biến độc lập (input). Ví dụ: dự đoán giá cổ phiếu ngày mai dựa trên dữ liệu thị trường hôm nay.
Một số loại mô hình hồi quy phổ biến:
Linear Regression (Hồi quy tuyến tính)
Ridge Regression, Lasso Regression (hồi quy có điều chuẩn)
Polynomial Regression (hồi quy đa thức)
Ví dụ thực tế: Dự đoán chỉ số VN-Index cuối ngày dựa trên khối lượng giao dịch, chỉ báo RSI, và thông tin thị trường quốc tế.
2. Classification – Phân loại
Classification là kỹ thuật học có giám sát dùng để dự đoán nhãn hoặc lớp của một dữ liệu. Kết quả đầu ra thường là nhị phân (ví dụ: “rủi ro” hoặc “an toàn”), hoặc phân loại đa lớp.
Một số thuật toán phân loại phổ biến:
Logistic Regression (mặc dù tên là regression, nhưng là thuật toán phân loại)
Decision Tree, Random Forest
Support Vector Machine (SVM)
Neural Networks
Ví dụ thực tế: Phân loại khách hàng có khả năng vỡ nợ (bad credit) hay không (good credit) dựa trên lịch sử tín dụng, thu nhập và số lượng tài sản.
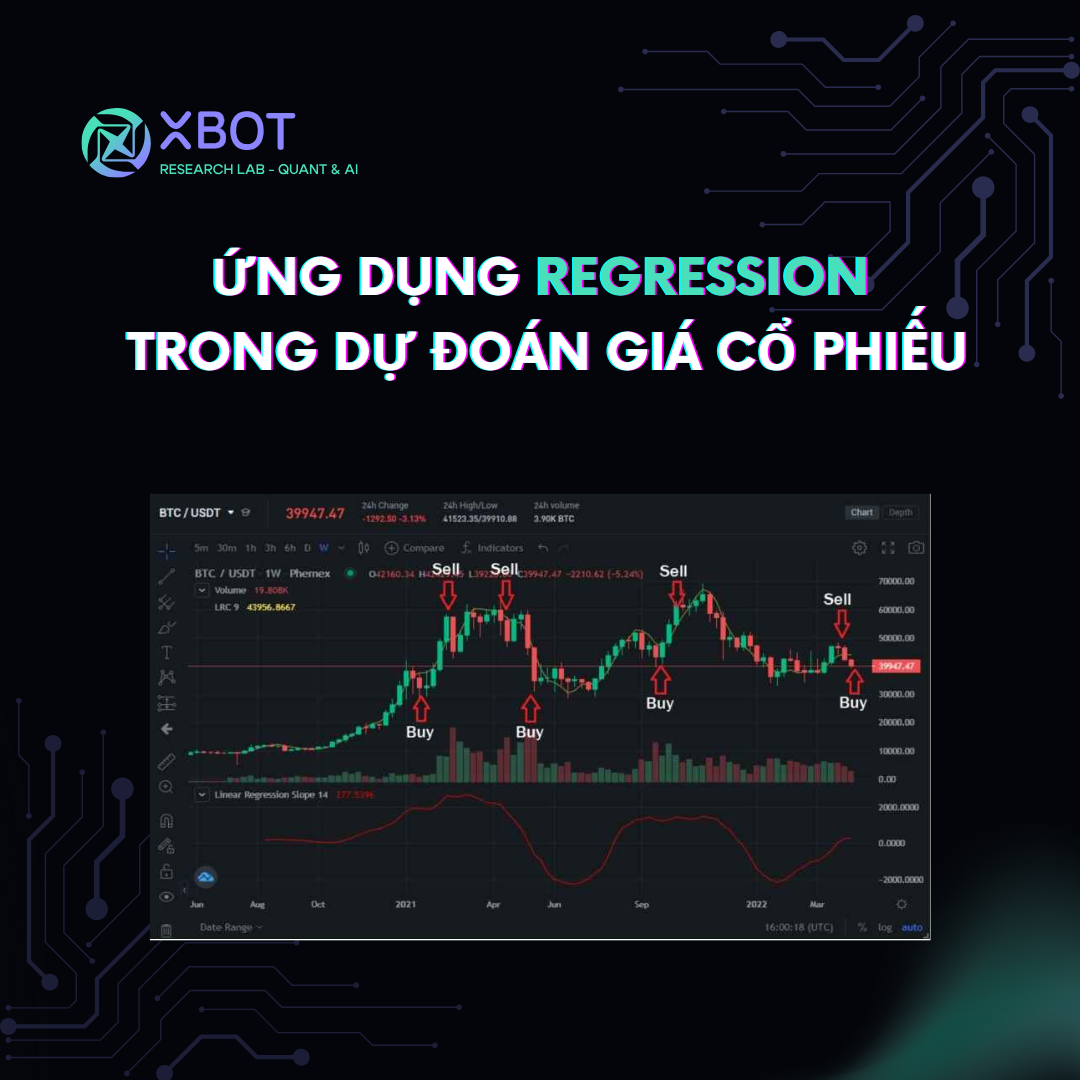
Ứng dụng của Hồi quy (Regression)
1. Dự đoán giá cổ phiếu và thị trường
Hồi quy là một công cụ quan trọng trong việc xây dựng các mô hình dự báo giá cổ phiếu. Bằng cách phân tích các chỉ số tài chính như dòng tiền, lãi suất, và các yếu tố kinh tế vĩ mô, nhà đầu tư có thể ước lượng giá trị tương lai của một cổ phiếu hoặc chỉ số thị trường.
Nghiên cứu tiêu biểu:
Theo nghiên cứu của Tsai & Hsiao (2010), mô hình hồi quy đa biến sử dụng các chỉ báo kỹ thuật như trung bình động (moving average), chỉ số sức mạnh tương đối (RSI – Relative Strength Index), và động lượng (momentum) đã giúp cải thiện độ chính xác trong dự báo thị trường chứng khoán Đài Loan.
2. Dự đoán lợi nhuận doanh nghiệp
Hồi quy cũng thường được sử dụng để ước tính doanh thu hoặc lợi nhuận của doanh nghiệp dựa trên các yếu tố như dữ liệu bán hàng, chi phí hoạt động, và chiến lược kinh doanh. Nhờ đó, các nhà phân tích có thể đưa ra các chiến lược đầu tư hợp lý và dự báo được khả năng tăng trưởng tài chính trong tương lai.
3. Quản trị danh mục đầu tư (Portfolio Management)
Mô hình hồi quy tuyến tính thường được sử dụng để tính toán beta – một thông số trong mô hình CAPM (Capital Asset Pricing Model). Beta đo lường mức độ biến động của một cổ phiếu so với thị trường chung, từ đó giúp các nhà quản lý danh mục đầu tư xác định mức độ rủi ro hệ thống và ra quyết định phân bổ tài sản hiệu quả.
Ứng dụng của Phân loại (Classification)
1. Phân loại rủi ro tín dụng
Các tổ chức tài chính sử dụng kỹ thuật phân loại để đánh giá và phân nhóm khách hàng dựa trên khả năng trả nợ – thường chia thành nhóm khách hàng tốt, trung bình, và có rủi ro cao. Các mô hình như Logistic Regression, Cây quyết định (Decision Tree), hoặc SVM có thể dự đoán khả năng khách hàng vỡ nợ dựa trên dữ liệu lịch sử tín dụng, thu nhập, độ tuổi, và các chỉ số nhân khẩu học khác.
Nghiên cứu tiêu biểu:
Baesens et al. (2003) đã chỉ ra rằng các mô hình phân loại tiên tiến như Mạng nơ-ron nhân tạo (Neural Networks) và Máy vector hỗ trợ (SVM) vượt trội hơn Logistic Regression trong việc phát hiện khách hàng có nguy cơ vỡ nợ.
2. Phát hiện gian lận tài chính (Fraud Detection)
Classification là công cụ then chốt trong việc phát hiện các hành vi gian lận trong tài chính. Các mô hình học máy có khả năng phân tích hành vi giao dịch và nhận diện các mẫu bất thường trong thời gian thực – chẳng hạn như giao dịch lớn vào khung giờ bất thường, hoặc các hành động không phù hợp với hành vi lịch sử của người dùng.
Ví dụ: nếu một khách hàng thường chỉ giao dịch trong giờ hành chính nhưng lại có một giao dịch rất lớn vào lúc nửa đêm, mô hình sẽ cảnh báo rằng đây có thể là hành vi gian lận.
3. Tư vấn đầu tư và phân khúc khách hàng
Phân loại khách hàng theo hồ sơ rủi ro, thói quen chi tiêu hoặc hành vi đầu tư cho phép các công ty tài chính cá nhân hóa chiến lược tư vấn, cung cấp giải pháp phù hợp với từng nhóm khách hàng. Việc này không chỉ nâng cao trải nghiệm người dùng mà còn giúp tối ưu hóa hiệu quả đầu tư và xây dựng mối quan hệ lâu dài giữa khách hàng và công ty tài chính.
Kết luận
Hiểu rõ sự khác biệt giữa Regression và Classification là bước đầu quan trọng khi ứng dụng học máy vào thị trường tài chính. Trong khi Regression giúp dự báo các giá trị tài chính liên tục như giá cổ phiếu hay lợi nhuận, thì Classification lại mạnh mẽ trong việc phát hiện rủi ro, gian lận và phân loại khách hàng.
Đối với người mới bắt đầu, việc lựa chọn đúng loại bài toán và thuật toán phù hợp sẽ giúp tăng hiệu quả trong việc xây dựng mô hình tài chính thực tiễn.
Tài liệu tham khảo (APA 7th)
Carcillo, F., Dal Pozzolo, A., Le Borgne, Y. A., Caelen, O., Mazzer, Y., & Bontempi, G. (2019). Scarff: a scalable framework for streaming credit card fraud detection with spark. Information Fusion, 41, 182–194. https://doi.org/10.1016/j.inffus.2017.09.005
Malekipirbazari, M., & Aksakalli, V. (2015). Risk assessment in social lending via random forests. Expert Systems with Applications, 42(10), 4621-4631. https://doi.org/10.1016/j.eswa.2015.01.002
Patel, J., Shah, S., Thakkar, P., & Kotecha, K. (2015). Predicting stock and stock price index movement using Trend Deterministic Data Preparation and machine learning techniques. Expert Systems with Applications, 42(1), 259-268. https://doi.org/10.1016/j.eswa.2014.08.009
Géron, A. (2019). Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow (2nd ed.). O’Reilly Media.
James, G., Witten, D., Hastie, T., & Tibshirani, R. (2021). An Introduction to Statistical Learning (2nd ed.). Springer.