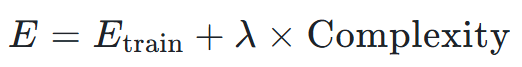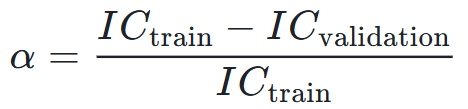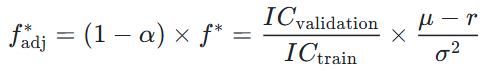Overfitting là gì? 3 "Tấm Khiên"chống Overfitting hiệu quả
Overfitting là gì? 3 "Tấm Khiên"chống Overfitting hiệu quả
Sau nhiều tuần nghiên cứu, bạn tạo ra một chiến lược giao dịch trông "đẹp như mơ" trên dữ liệu quá khứ. Đường cong vốn tăng trưởng mượt mà, tỷ lệ Sharpe ấn tượng. Nhưng khi đưa vào thực chiến (live trading), nó lại sụp đổ nhanh chóng.
Nếu câu chuyện này nghe quen thuộc, rất có thể bạn đã trở thành nạn nhân của Overfitting (hay Quá khớp) – một trong những cạm bẫy nguy hiểm và phổ biến nhất trong giao dịch định lượng.
Overfitting xảy ra khi mô hình của bạn không học được quy luật thực sự của thị trường, mà lại "học thuộc lòng" cả những nhiễu ngẫu nhiên và các sự kiện chỉ xảy ra một lần trong quá khứ. Theo phân tích của chúng tôi, kết quả là một chiến lược hoạt động như một thiên tài trong backtest nhưng lại hành xử như một người chơi cờ bạc đầy cảm tính khi đối mặt với dữ liệu mới.
Vậy làm thế nào để xây dựng những chiến lược không chỉ tốt trên giấy tờ mà còn vững vàng trong thực tế?
Trong bài viết này, hãy cùng XNO Quant khám phá 3 "tấm khiên" vững chắc để bảo vệ chiến lược của bạn khỏi overfitting. Đây là những phương pháp được chắt lọc từ các nghiên cứu học thuật nhưng được diễn giải một cách gần gũi, dành cho mọi nhà đầu tư tại Việt Nam.
Chúng ta sẽ cùng nhau tìm hiểu:
Kiểm soát độ phức tạp: Làm thế nào để giữ mô hình đơn giản mà vẫn hiệu quả?
Phát hiện sớm: Cách nhận biết overfitting ngay khi nó mới bắt đầu nhen nhóm.
Điều chỉnh vốn thông minh: Làm gì khi mô hình của bạn có dấu hiệu quá tự tin?
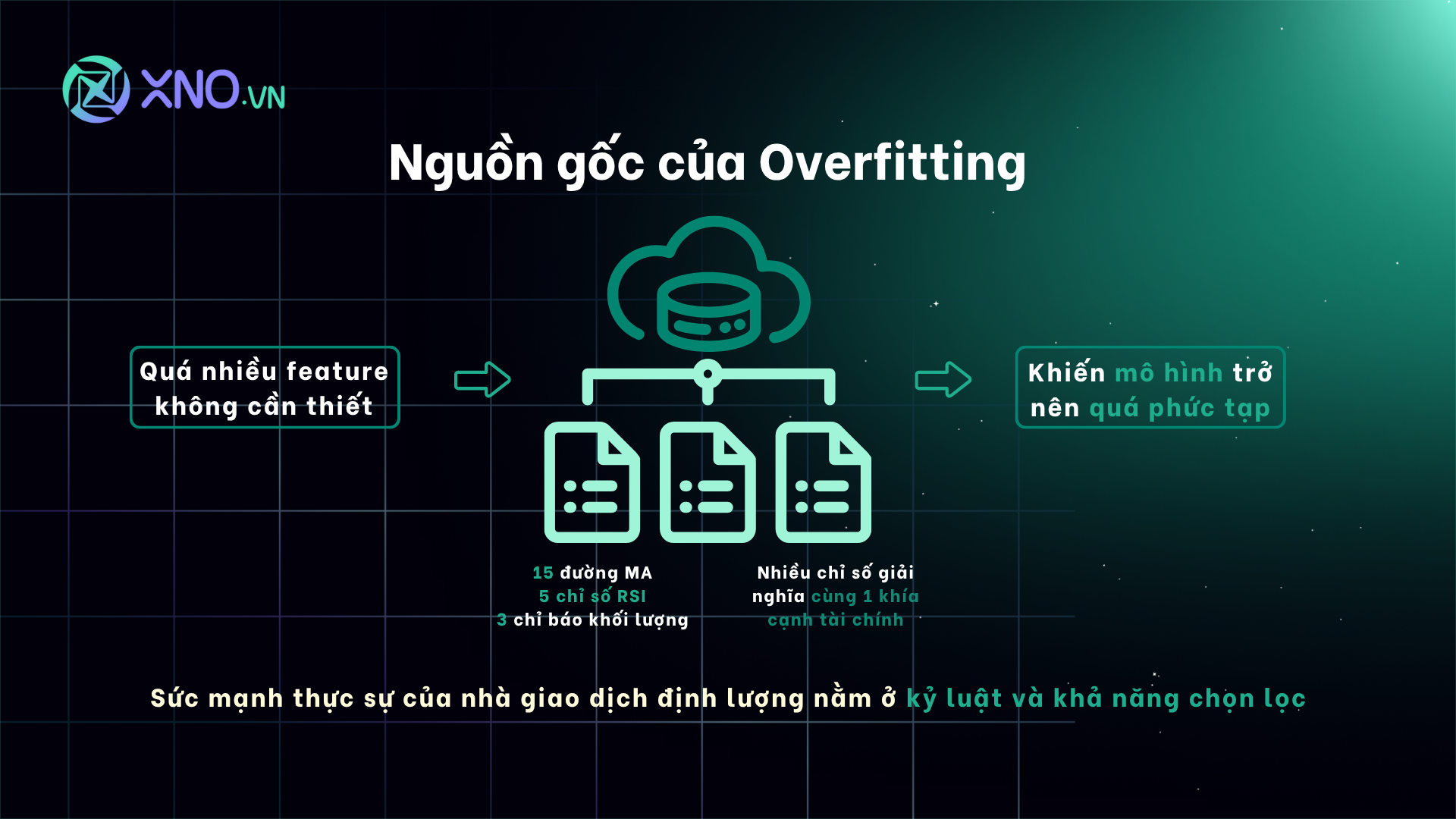
1. Nguồn Gốc Của Overfitting: Sự Phức Tạp Từ Feature Engineering
Trước khi tìm cách chữa bệnh, chúng ta cần hiểu căn nguyên của nó. Một trong những nguồn gốc chính gây ra overfitting chính là Kỹ thuật Tạo Đặc Trưng (Feature Engineering).
Đây là quá trình biến dữ liệu thô (giá, khối lượng, báo cáo tài chính) thành các biến số có ý nghĩa hơn, gọi là đặc trưng (features), để "mớm" cho mô hình. Đặc trưng tốt sẽ giúp mô hình tìm ra lợi thế cạnh tranh (alpha). Nhưng quá nhiều đặc trưng, hoặc các đặc trưng không liên quan, sẽ dẫn thẳng đến overfitting.
Độ phức tạp đến từ đâu?
Điển hình cho việc một nhà đầu tư có thể vô tình tạo ra một mô hình quá phức tạp có thể kể đến:
Chỉ báo Kỹ thuật (TA): Một nhà đầu tư cố gắng "ép" mô hình phải khớp hoàn hảo với các đỉnh/đáy lịch sử của cổ phiếu HPG. Anh ta sử dụng 15 đường MA khác nhau (từ MA5 đến MA200), 5 loại RSI, và thêm 3 chỉ báo về khối lượng. Mô hình này có thể sẽ hoạt động hoàn hảo trên quá khứ của HPG, nhưng gần như chắc chắn sẽ thất bại với các cổ phiếu khác hoặc ngay cả với chính HPG trong tương lai.
Dữ liệu Cơ bản (Fundamental): Mô hình sử dụng 10 chỉ số khác nhau về đòn bẩy tài chính (ví dụ: Vốn CSH/Tổng tài sản, Nợ/Vốn CSH, Leverage), trong khi thực tế chúng đều phản ánh cùng một khía cạnh của doanh nghiệp. Điều này chỉ làm tăng nhiễu và sự dư thừa thông tin.
Bài học cốt lõi: Mặc dù các hệ thống như XNO Quant có thể tự động sinh ra hàng trăm chỉ báo kỹ thuật và chỉ số tài chính, sức mạnh thực sự của nhà giao dịch định lượng nằm ở kỷ luật và khả năng chọn lọc. Chúng ta phải chủ động kiểm soát sự phức tạp này ngay từ bước đầu tiên. Nhà đầu tư cần lưu ý rằng cần cân nhắc chọn "đủ" feature cho giả thuyết của mình, nếu không cũng có thể dẫn đến underfitting.
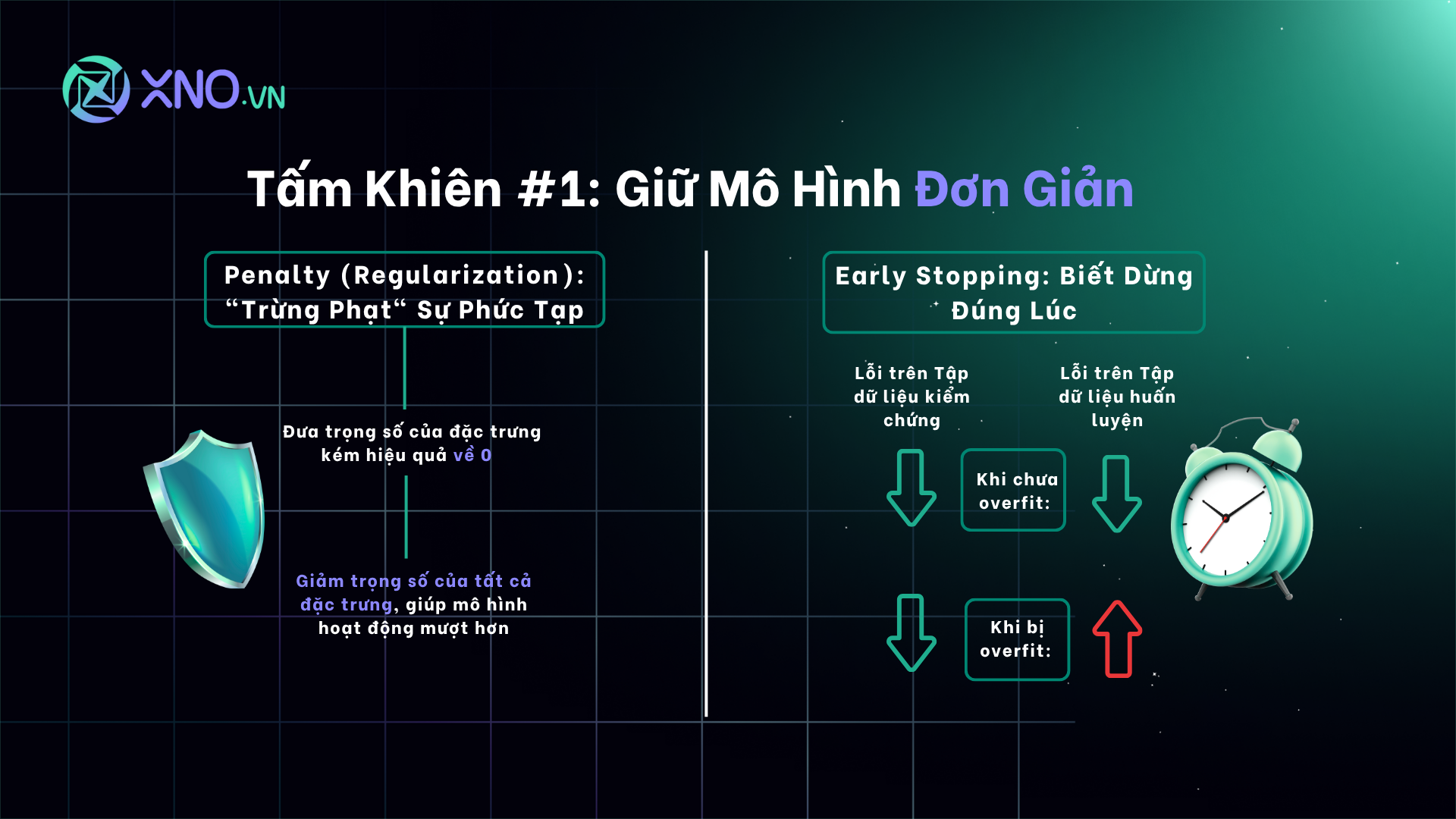
2. Tấm Khiên Chống Overfitting #1: Giữ Mô Hình Đơn Giản (Penalty & Early Stopping)
Hai phương pháp Penalty (Trừng phạt) và Early Stopping (Dừng sớm) có chung một mục tiêu: kiểm soát năng lực của mô hình (model capacity) – tức là khả năng mô hình có thể "vặn vẹo" để khớp với những chi tiết nhỏ nhất trong dữ liệu.
Penalty (Regularization): "Trừng Phạt" Sự Phức Tạp
Hãy tưởng tượng bạn đang huấn luyện một nhân viên mới. Thay vì chỉ thưởng cho kết quả (giảm lỗi), bạn còn "phạt" nếu họ dùng những quy trình quá phức tạp, khó áp dụng. Penalty trong machine learning cũng hoạt động tương tự.
Thay vì chỉ tìm cách giảm lỗi trên dữ liệu huấn luyện E_train, thuật toán sẽ tối ưu hóa một mục tiêu mới:
Trong đó, yếu tố hình phạt "lambda x complexity" (độ phức tạp) sẽ tăng lên khi mô hình trở nên quá cồng kềnh (ví dụ: sử dụng quá nhiều đặc trưng hoặc các trọng số của đặc trưng quá lớn).
L1 Regularization (Lasso): Các nhà đầu tư sẽ cần thẳng tay loại bỏ hoàn toàn những đặc trưng kém hiệu quả bằng cách đưa trọng số của chúng về 0. Điều này giúp mô hình tự động chọn lọc đặc trưng.
L2 Regularization (Ridge): Giống như một người quản lý ôn hòa hơn, nó không sa thải (loại bỏ) ai nhưng sẽ giảm "lương" (trọng số) của tất cả mọi người, khiến không ai có ảnh hưởng quá lớn, giúp mô hình hoạt động mượt mà hơn.
Bằng cách áp đặt "chi phí" cho sự phức tạp, chúng ta khuyến khích mô hình tìm ra những giải pháp đơn giản và dễ khái quát hóa hơn.
Early Stopping: Biết Dừng Đúng Lúc
Đây là một kỹ thuật cực kỳ trực quan. Trong quá trình huấn luyện, chúng ta sẽ liên tục kiểm tra hiệu suất của mô hình trên một tập dữ liệu kiểm chứng (Validation set) – là dữ liệu mà mô hình chưa từng thấy.
Ban đầu, khi mô hình học được các quy luật chung, lỗi trên cả tập huấn luyện và tập kiểm chứng đều giảm.
Đến một thời điểm, mô hình bắt đầu "học vẹt" những chi tiết nhiễu của tập huấn luyện. Lỗi huấn luyện tiếp tục giảm, nhưng lỗi trên tập kiểm chứng bắt đầu tăng lên.
Nguyên tắc vàng là: dừng huấn luyện ngay tại điểm đó – khoảnh khắc hiệu suất trên tập kiểm chứng ngừng cải thiện. Điều này đảm bảo chúng ta giữ lại được phiên bản mô hình tốt nhất, nắm bắt được quy luật cốt lõi mà không bị cuốn theo những biến động ngẫu nhiên.
Ứng Dụng Thực Tế
Là một nhà đầu tư cá nhân, bạn có thể áp dụng tư duy này một cách đơn giản:
Luôn phân chia dữ liệu: Chia dữ liệu lịch sử thành 3 phần: Huấn luyện (Training), Kiểm chứng (Validation), và Kiểm tra cuối cùng (Out-of-Sample Test).
Kỷ luật khi tối ưu hóa: Chỉ tinh chỉnh các tham số (ví dụ: chu kỳ của RSI, MA) trên tập Training.
Theo dõi hiệu suất kiểm chứng: Sau mỗi lần tinh chỉnh, hãy xem hiệu suất trên tập Validation. Hãy dừng lại khi hiệu suất trên tập này không còn cải thiện đáng kể, ngay cả khi hiệu suất trên tập Training vẫn tiếp tục tăng.
Đây là những rào cản tự nhiên giúp bạn chống lại ham muốn "tối ưu hóa quá mức" và giữ cho hệ thống đủ đơn giản để hoạt động hiệu quả trên thực tế.
3. Tấm Khiên Chống Overfitting #2: Theo Dõi Quá Trình Học (Logic OverfitGuard)
Mỗi mô hình khi được huấn luyện đều tạo ra một đường cong học tập (learning curve). Đây là biểu đồ thể hiện lỗi huấn luyện và lỗi kiểm chứng thay đổi như thế nào qua thời gian. Hình dạng của đường cong này sẽ tiết lộ "sức khỏe" của mô hình:
Quá trình Học Lành mạnh: Lỗi huấn luyện và lỗi kiểm chứng cùng nhau giảm xuống rồi đi vào ổn định.
Kịch bản Overfitting: Lỗi huấn luyện tiếp tục giảm (mô hình đang học vẹt), trong khi lỗi kiểm chứng bắt đầu tăng lên (mô hình mất khả năng khái quát hóa). Khoảng cách giữa hai đường này ngày càng lớn.
Nghe sơ qua thì khá giống early stopping, tuy nhiên logic của logic overfitGuard thì lại khác: Xây dựng một "bộ phát hiện" có khả năng nhận dạng hình dạng đặc trưng của một đường cong overfitting. Khi nó nhận thấy lỗi kiểm chứng bắt đầu leo thang, nó sẽ tự động kích hoạt cơ chế dừng sớm.
Ứng Dụng Thực Tế
Chúng ta hiếm khi huấn luyện các mạng nơ-ron phức tạp, nhưng logic này vẫn vô cùng giá trị:
Ghi lại hiệu suất: Sau mỗi lần bạn tinh chỉnh tham số, hãy ghi lại Tỷ lệ Sharpe (hoặc một chỉ số hiệu suất bạn tin cậy) trên cả tập Training và tập Validation.
Vẽ biểu đồ: Vẽ hai đường hiệu suất này lên cùng một biểu đồ.
Tìm kiếm sự phân kỳ: Nếu bạn thấy đường hiệu suất trên tập Training cứ tiếp tục tăng trong khi đường trên tập Validation bắt đầu đi ngang hoặc đi xuống, đó chính là tín hiệu cảnh báo đỏ. Hãy dừng việc tối ưu hóa lại.
Về bản chất, phương pháp này biến nghệ thuật "biết khi nào nên dừng" thành một quy trình có cấu trúc, dựa trên dữ liệu thực tế. Ngay cả việc theo dõi các chỉ số này trên một bảng tính đơn giản cũng đã là một bước tiến lớn.
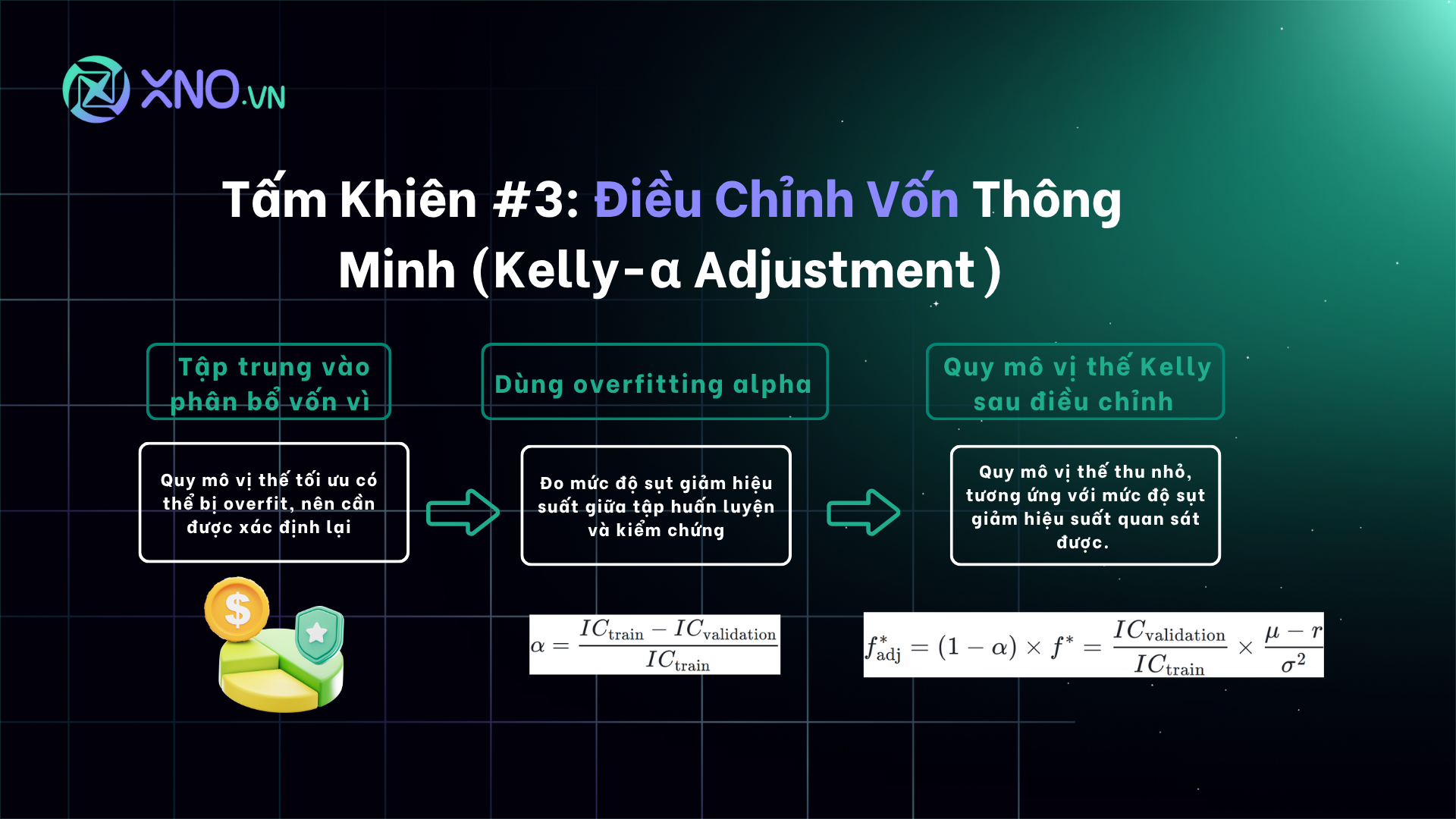
4. Tấm Khiên Chống Overfitting #3: Điều Chỉnh Vốn Thông Minh (Kelly-α Adjustment)
Tấm khiên cuối cùng này không can thiệp vào việc xây dựng mô hình, mà tập trung vào phân bổ vốn. Nó giúp giới hạn thiệt hại khi mô hình của bạn trở nên quá tự tin.
Phương pháp này bắt nguồn từ Tiêu chí Kelly nổi tiếng, một công thức toán học để xác định quy mô vị thế tối ưu. Tuy nhiên, công thức Kelly gốc giả định rằng chúng ta biết chính xác lợi thế của mình. Trong thực tế, lợi thế này thường bị phóng đại do overfitting.
Để khắc phục, chúng ta sẽ đo lường mức độ sụt giảm hiệu suất giữa tập Training và tập Validation. Tỷ lệ sụt giảm này được gọi là hệ số overfitting alpha:
Trong đó, IC (Information Coefficient) là một thước đo tương quan giữa lợi nhuận dự báo và lợi nhuận thực tế.
Khi alpha nhỏ, hiệu suất trên hai tập dữ liệu là tương tự → ít overfitting.
Khi alpha gần bằng 1, hiệu suất trên tập Validation sụp đổ so với tập Training → overfitting nghiêm trọng.
Quy mô vị thế Kelly sau khi điều chỉnh sẽ là:
Nói đơn giản, quy mô vị thế sẽ được thu nhỏ lại, tương ứng với mức độ sụt giảm hiệu suất mà chúng ta quan sát được. Khi overfitting càng tệ, chúng ta càng đặt cược ít hơn.
Ứng Dụng Thực Tế
Bạn có thể áp dụng logic này một cách trực quan mà không cần đến các công thức phức tạp. Thay vì IC, hãy sử dụng Tỷ lệ Sharpe:
Ví dụ thực tế với Cổ phiếu PVS:
Tỷ lệ Sharpe trên tập Training (Backtest) = 1.5
Tỷ lệ Sharpe trên tập Validation (Kiểm chứng) = 0.9
Rõ ràng, mô hình này đang có sự sụt giảm hiệu suất đáng kể khi đối mặt với dữ liệu mới.
Hệ số Điều chỉnh (Shrink Factor) =
Điều này có nghĩa là bạn chỉ nên sử dụng 60% quy mô vị thế so với tính toán ban đầu. Nếu bình thường bạn dự định vào lệnh với 10% vốn, thì bây giờ bạn chỉ nên mạo hiểm 6%.
Bằng cách này, chúng ta chấp nhận hy sinh một phần lợi nhuận tiềm năng để bảo vệ vốn khỏi rủi ro thua lỗ do đã đánh giá quá cao lợi thế của mô hình.
Kết luận: Khi kết quả kiểm chứng yếu hơn kết quả backtest, hãy giảm quy mô đặt cược. Độ chênh lệch càng lớn, bạn càng phải thận trọng hơn.
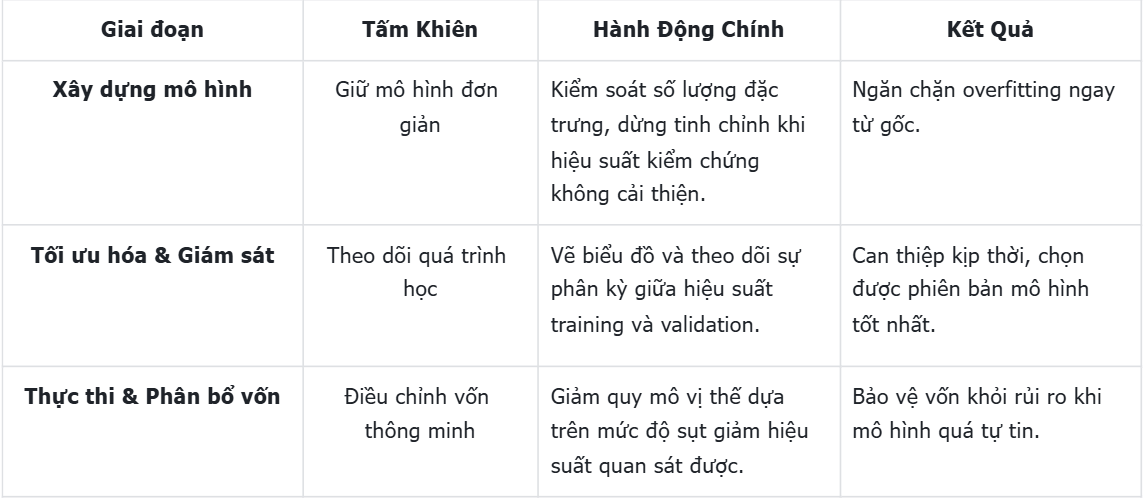
Tóm tắt nội dung 3 phương pháp chống Overfitting:
Ba "tấm khiên" này bổ sung cho nhau một cách hoàn hảo, giúp chúng ta chuyển từ thế bị động sang chủ động trong cuộc chiến chống overfitting:
Đối với nhà đầu tư cá nhân, những khái niệm này có thể được đúc kết thành một quy trình làm việc rõ ràng:
Luôn tách biệt dữ liệu thành các phần Training, Validation và Test.
Quan sát hiệu suất trên tập Validation trong suốt quá trình tối ưu hóa; dừng lại khi nó không còn cải thiện.
So sánh các chỉ số hiệu suất giữa các tập dữ liệu để ước tính mức độ overfitting.
Điều chỉnh quy mô vị thế một cách thận trọng.
Kết Luận: Tích Hợp 3 Tấm Khiên Để Nâng Tầm Giao Dịch
Dựa trên dữ liệu thực tế, cuộc chiến chống overfitting không nằm ở việc tìm ra đoạn code phức tạp nhất. Nó nằm ở sự tôn trọng tính không chắc chắn của thị trường, đo lường nó, và quản lý nó bằng kỷ luật*. Điều này biến overfitting từ một mối đe dọa vô hình thành một rủi ro có thể đo lường và kiểm soát được.
Hãy nhớ rằng, XNO Quant luôn đồng hành cùng bạn từng bước trên hành trình này. Nền tảng của chúng tôi cung cấp dữ liệu sạch và các công cụ backtesting chuyên nghiệp để bạn có thể tập trung vào việc áp dụng các nguyên tắc này, hướng tới việc xây dựng một cộng đồng giao dịch thông minh và bền vững.
Hiện tạiXNO Quant cung cấp sân chơi toàn diện cho các nhà giao dịch định lượng. Nền tảng trang bị API dữ liệu real-time, backtesting và paper trading để thử nghiệm mô hình chuyên nghiệp. Định kỳ hàng quý, chúng tôi sẽ rót vốn đầu tư và trao thưởng cho các mô hình lợi nhuận cao nhất, giúp bạn nâng cao uy tín và cơ hội việc làm.
Song song đó, chúng tôi xây dựng cộng đồng Quant & AI Việt Nam - Đầu tư định lượng với các workshop offline hàng thángdo chuyên gia chủ trì. Mọi kiến thức và video workshop đều được chia sẻ công khai trên Fanpage. Hãy trở thành một phần của cộng đồng này để cùng nhau chia sẻ chuyên môn và phát kỹ năng giao dịch định lượng của bạn.