Hướng dẫn toàn diện về xử lý dữ liệu lớn trong giao dịch định lượng
Hướng dẫn toàn diện về xử lý dữ liệu lớn trong giao dịch định lượng
Lợi thế cạnh tranh trong đầu tư định lượng ngày nay không còn đến từ việc phân tích báo cáo tài chính hay nhận định vĩ mô đơn thuần. Nó đang dần chuyển dịch sang việc ai có khả năng xử lý dữ liệu tốt hơn, nhanh hơn và sâu hơn., các quỹ đầu tư định lượng (quant trading firms) đang phải đối mặt với một thách thức lớn: làm thế nào để xử lý, lưu trữ và biến khối lượng dữ liệu khổng lồ này thành những chiến lược giao dịch sinh lời. Quá trình này, còn được gọi là xử lý dữ liệu lớn, chính là nền tảng cốt lõi để tạo ra alpha trong kỷ nguyên số.
Bài viết này sẽ đi sâu vào từng khía cạnh của quy trình xử lý big data trong giao dịch định lượng, từ việc xác định nguồn dữ liệu đến xây dựng hạ tầng và mô hình phân tích. Chúng ta sẽ cùng nhau khám phá một hệ sinh thái phức tạp nhưng vô cùng mạnh mẽ, nơi mà mỗi bước đi đều có thể quyết định sự thành bại của một chiến lược.
1. Phân loại Các Nguồn dữ liệu lớn
Hãy nhớ kỹ: Một chiến lược định lượng chỉ có thể tốt bằng chất lượng của dữ liệu đầu vào. Các nguồn dữ liệu trong giao dịch định lượng không chỉ giới hạn ở thông tin thị trường truyền thống mà còn mở rộng ra nhiều loại dữ liệu phi cấu trúc và thay thế khác.
Dữ liệu Thị trường: Đây là nguồn dữ liệu cơ bản và không thể thiếu. Nó bao gồm các giao dịch (trades), báo giá (quotes) ở cấp độ tick, và dữ liệu thanh khoản của sổ lệnh (order book). Với tần suất cập nhật liên tục, dữ liệu này đòi hỏi một hệ thống thu thập và xử lý tốc độ cao để đảm bảo tính kịp thời. Bên cạnh đó, dữ liệu lịch sử về giá mở cửa, cao nhất, thấp nhất, đóng cửa và khối lượng (OHLCV) theo ngày hoặc theo khung thời gian nhỏ hơn (intraday bars) là yếu tố cần thiết cho việc kiểm thử lịch sử (backtesting) và phân tích hành vi giá trong quá khứ, giúp các mô hình học máy nhận diện các mô hình thị trường một cách hiệu quả.
Dữ liệu Cơ bản: Ngoài các báo cáo tài chính truyền thống của doanh nghiệp, các nhà giao dịch định lượng ngày nay còn tìm kiếm lợi thế từ các nguồn dữ liệu cơ bản thay thế. Điều này bao gồm dữ liệu chuỗi cung ứng (supply chain data), dữ liệu chi tiêu thẻ tín dụng (credit card spending) để ước tính doanh thu của các công ty bán lẻ, và thậm chí là báo cáo từ các nhà phân tích. Những nguồn dữ liệu này thường cung cấp cái nhìn sớm và chi tiết hơn về sức khỏe tài chính của một doanh nghiệp so với các báo cáo tài chính công bố định kỳ, giúp mô hình của bạn có được thông tin sớm hơn thị trường.
Dữ liệu Thay thế: Đây là biên giới mới của việc xử lý dữ liệu lớn. Dữ liệu thay thế là bất kỳ thông tin nào không phải là dữ liệu thị trường hay dữ liệu cơ bản truyền thống. Nó bao gồm dữ liệu từ các trang web được thu thập qua web scraping (ví dụ: tin tức, dữ liệu tâm lý từ mạng xã hội), hình ảnh vệ tinh để theo dõi sản lượng nông nghiệp hoặc hoạt động của các nhà máy, dữ liệu vị trí địa lý (geolocation) để theo dõi lưu lượng khách hàng đến các cửa hàng bán lẻ, và dữ liệu ESG (Môi trường, Xã hội và Quản trị) để đánh giá rủi ro bền vững. Việc xử lý những nguồn dữ liệu này thường rất phức tạp do tính phi cấu trúc và đa dạng của chúng.
Dữ liệu Phái sinh: Dữ liệu phái sinh là kết quả của việc xử lý dữ liệu thô để tạo ra các biến số có tính dự báo cao hơn cho các mô hình. Ví dụ điển hình là các chỉ báo kỹ thuật (như RSI, MACD, đường trung bình động), các tín hiệu nhân tố (như SMB, HML trong mô hình Fama-French), hay các biến số phức tạp hơn được tạo ra đặc biệt cho các mô hình học máy. Việc này đòi hỏi kỹ thuật feature engineering (kỹ thuật trích xuất đặc trưng) chuyên sâu, bao gồm việc tính toán các biến trễ (lagged variables), thống kê cửa sổ trượt (rolling windows), và ước tính biến động (volatility estimates) để tạo ra các tín hiệu có ý nghĩa hơn cho các thuật toán.
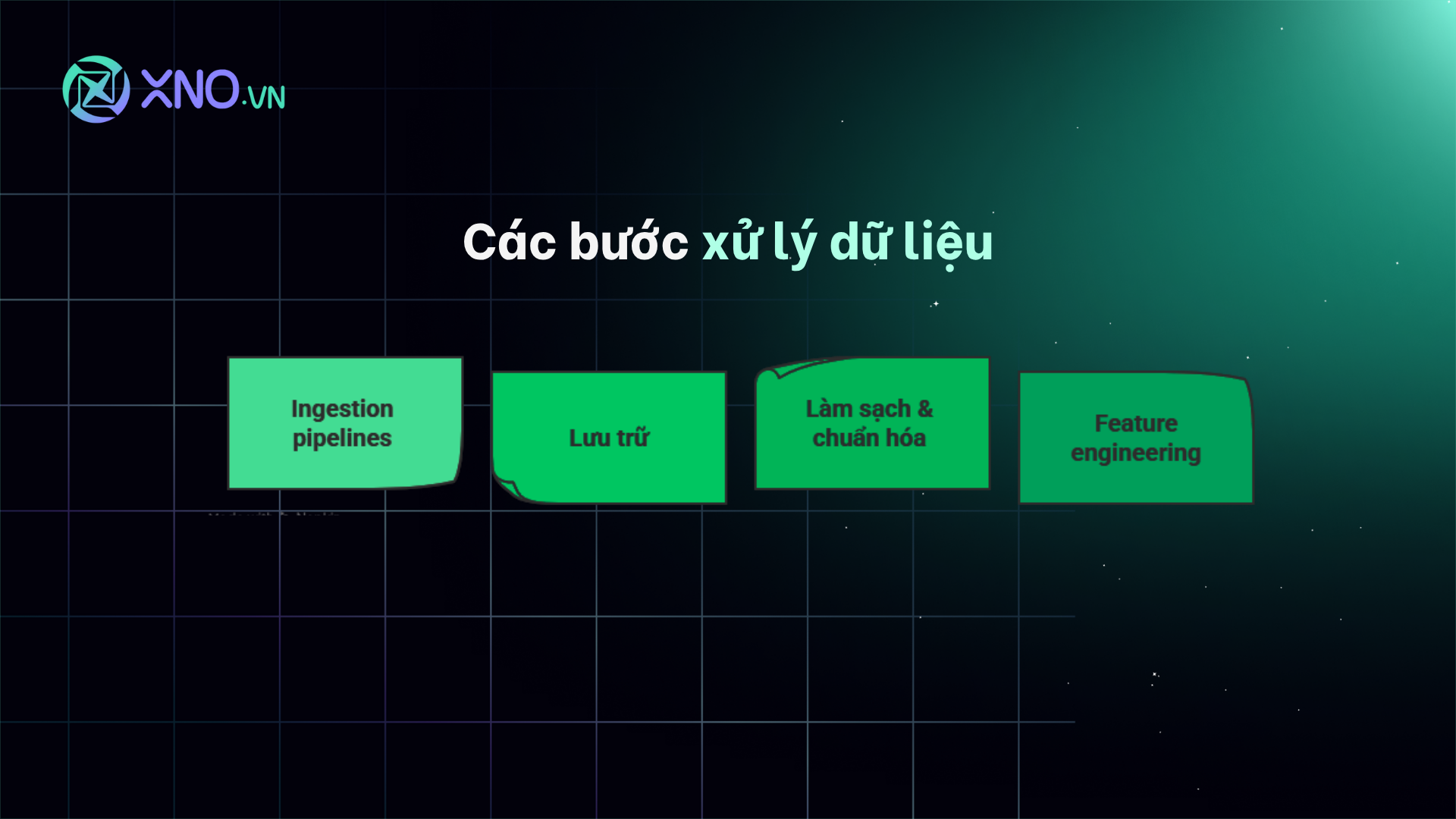
2. Cách lưu trữ Và chuẩn bị Dữ liệu lớn Trước khi Xử lý
Sau khi xác định nguồn dữ liệu, việc tiếp theo là xây dựng một quy trình ổn định và hiệu quả để lưu trữ và chuẩn bị dữ liệu cho phân tích. Đây là công đoạn cốt lõi của công nghệ xử lý dữ liệu lớn.
Hệ thống Thu thập (Ingestion Pipelines): Dữ liệu tài chính đến với tốc độ và khối lượng khác nhau. Các API (Application Programming Interfaces) và FIX feeds là những kênh chính để nhận dữ liệu thời gian thực từ các sàn giao dịch. Trong khi đó, các trình thu thập dữ liệu web (web crawlers) được sử dụng để lấy dữ liệu phi cấu trúc từ các trang web. Việc xử lý dữ liệu có thể được thực hiện theo batch (xử lý hàng loạt) cho dữ liệu lịch sử, hoặc theo streaming (xử lý dòng) cho dữ liệu trực tiếp, nhằm đáp ứng nhu cầu giao dịch tần suất cao.
Giải pháp Lưu trữ: Việc lựa chọn giải pháp lưu trữ phù hợp là vô cùng quan trọng. Các cơ sở dữ liệu quan hệ (relational DBs) như PostgreSQL hay MySQL vẫn được sử dụng cho các dữ liệu có cấu trúc đơn giản. Tuy nhiên, với dữ liệu thị trường có tính chất chuỗi thời gian, các cơ sở dữ liệu chuyên dụng như InfluxDB hoặc kdb+ (được tối ưu hóa cho tài chính) là lựa chọn tối ưu. Đối với các nguồn dữ liệu phi cấu trúc khổng lồ, các giải pháp lưu trữ phân tán như HDFS hay Amazon S3 là cần thiết, giúp lưu trữ và truy xuất dữ liệu một cách linh hoạt.
Làm sạch & Chuẩn hóa: Dữ liệu thô hiếm khi hoàn hảo. Trước khi đưa vào mô hình, nó cần được làm sạch và chuẩn hóa. Điều này bao gồm việc điều chỉnh cho các sự kiện doanh nghiệp như chia tách cổ phiếu, trả cổ tức, xử lý các giá trị bị thiếu hoặc trùng lặp, và loại bỏ các dữ liệu ngoại lai (outlier) có thể làm sai lệch kết quả mô hình. Quy trình này đòi hỏi sự tỉ mỉ và kiến thức chuyên môn sâu sắc về tài chính để đảm bảo tính toàn vẹn và độ chính xác của dữ liệu.
Kỹ thuật Trích xuất Đặc trưng (Feature Engineering): Đây là công đoạn biến dữ liệu thô thành các biến số có ý nghĩa đối với mô hình. Ví dụ, từ giá cổ phiếu, chúng ta có thể tạo ra các biến số như biến động giá trong 20 ngày gần nhất (rolling volatility), tỷ lệ thay đổi (rate of change), hay các tín hiệu phức tạp hơn. Trong trường hợp dữ liệu văn bản, chúng ta có thể sử dụng các kỹ thuật như Bag of Words hoặc Word Embeddings để biến các bài viết tin tức thành các vector số học biểu diễn tâm lý thị trường, từ đó đưa vào mô hình học máy để phân tích một cách hiệu quả.
3. Xử lý Và Tính toán Dữ liệu lớn
Đây là bước biến dữ liệu đã được chuẩn bị thành các tín hiệu giao dịch. Quá trình này đòi hỏi năng lực tính toán khổng lồ và các thuật toán phức tạp.
Xử lý Hàng loạt (Batch Processing): Dù thị trường có diễn biến theo thời gian thực, nhưng việc kiểm thử chiến lược giao dịch vẫn chủ yếu được thực hiện theo phương pháp xử lý hàng loạt. Các hệ thống xử lý dữ liệu lớn này sẽ lấy một khối lượng dữ liệu lịch sử khổng lồ, chạy mô hình, và mô phỏng kết quả giao dịch. Quá trình này giúp đánh giá hiệu suất của chiến lược trên nhiều điều kiện thị trường khác nhau và thực hiện các phân tích rủi ro chi tiết.
Xử lý Dòng (Stream Processing): Với các chiến lược giao dịch tần suất cao (high-frequency trading), tốc độ là yếu tố sống còn. Dữ liệu thị trường được xử lý theo thời gian thực, ngay khi nó được tạo ra, cho phép mô hình phát hiện các cơ hội giao dịch với độ trễ cực thấp. Các hệ thống này cần được thiết kế đặc biệt để xử lý một lượng lớn dữ liệu một cách liên tục và hiệu quả, đảm bảo tín hiệu giao dịch được tạo ra gần như ngay lập tức.
Khả năng Mở rộng (Scalability): Để xử lý khối lượng dữ liệu và các mô hình tính toán ngày càng phức tạp, khả năng mở rộng của hệ thống là một yêu cầu bắt buộc. Các nền tảng điện toán phân tán như Apache Spark hay Ray giúp chia nhỏ các tác vụ tính toán lớn thành nhiều tác vụ nhỏ hơn và xử lý chúng song song trên nhiều máy tính. Ngoài ra, việc sử dụng các GPU (đơn vị xử lý đồ họa) là một công nghệ xử lý dữ liệu lớn không thể thiếu cho các mô hình học sâu (deep learning), giúp tăng tốc độ xử lý lên hàng chục, thậm chí hàng trăm lần.
Kiểm tra Chất lượng Dữ liệu: Một mô hình được xây dựng trên dữ liệu kém chất lượng sẽ tạo ra kết quả kém. Để ngăn chặn các lỗi nghiêm trọng, các nhà giao dịch định lượng phải thực hiện các bước kiểm tra chất lượng dữ liệu nghiêm ngặt. Điều này bao gồm việc xác thực tính chính xác của dữ liệu tại một thời điểm cụ thể (point-in-time validation) để tránh "lỗi nhìn trước" (look-ahead bias) trong backtesting, và đảm bảo mô hình không bị ảnh hưởng bởi lỗi survivorship bias (chỉ phân tích các công ty còn tồn tại).
4. Mô hình Và Phân tích: Biến dữ liệu lớn thành chiến lược giao dịch cổ phiếu
Đây là giai đoạn mà dữ liệu được biến thành các quyết định đầu tư cụ thể thông qua các mô hình phân tích.
Mô hình Thống kê: Các mô hình thống kê truyền thống vẫn đóng vai trò quan trọng, đặc biệt là trong việc kiểm tra các giả thuyết. Ví dụ, mô hình nhân tố (factor models) giúp giải thích lợi nhuận của một cổ phiếu bằng cách phân tách nó thành các nhân tố rủi ro và alpha (phần lợi nhuận vượt trội). Phân tích thành phần chính (PCA) cũng được sử dụng để giảm chiều dữ liệu và tìm ra các mối quan hệ ẩn.
Học máy (Machine Learning): Đây là lĩnh vực đang bùng nổ trong giao dịch định lượng. Các mô hình học máy được sử dụng rộng rãi, từ học có giám sát (supervised learning) để dự đoán lợi nhuận hay biến động, học không giám sát (unsupervised learning) để phân loại các trạng thái thị trường hay phát hiện các bất thường, cho đến học tăng cường (reinforcement learning) để tối ưu hóa chiến lược khớp lệnh.
Kiểm thử Lịch sử (Backtesting) & Xác thực: Một chiến lược chỉ có giá trị khi nó hoạt động tốt trên dữ liệu quá khứ một cách đáng tin cậy. Các nhà giao dịch định lượng sử dụng các phương pháp như chia dữ liệu thành tập huấn luyện/kiểm thử (train/test splits) và kiểm thử bước tiến (walk-forward testing) để đảm bảo mô hình không chỉ hoạt động tốt trên dữ liệu cũ mà còn có khả năng sinh lời trong tương lai. Đặc biệt, việc kiểm soát các lỗi như multiple-testing bias (kiểm thử nhiều lần) là cần thiết để tránh những kết quả ngẫu nhiên.
Quản lý Rủi ro & Phân bổ: Dù mô hình có tốt đến đâu, việc quản lý rủi ro vẫn là ưu tiên hàng đầu. Dữ liệu được sử dụng để chạy các phân tích stress test và kịch bản (scenario analysis) nhằm đánh giá khả năng chịu đựng của chiến lược trước các sự kiện thị trường bất lợi. Phân tích các yếu tố (factor exposures) cũng giúp các nhà quản lý đảm bảo rằng danh mục đầu tư không quá tập trung vào một loại rủi ro cụ thể nào.
5. Hạ tầng Và Công cụ Hỗ trợ Phân tích Dữ liệu lớn
Để toàn bộ quy trình trên có thể vận hành trơn tru, một hệ thống hạ tầng và các công cụ xử lý dữ liệu lớn phù hợp là yếu tố quyết định.
Ngôn ngữ Lập trình & Thư viện: Python là ngôn ngữ phổ biến nhất trong giao dịch định lượng nhờ các thư viện mạnh mẽ như Pandas (xử lý dữ liệu), NumPy (toán học), và PySpark (điện toán phân tán). Tuy nhiên, với các hệ thống cần tốc độ cực cao, các ngôn ngữ như C++ hay Rust vẫn được ưu tiên. Mặc dù nhiều người mới bắt đầu có thể nghĩ đến việc xử lý dữ liệu lớn trong Excel, nhưng công cụ này hoàn toàn không đủ khả năng xử lý khối lượng và độ phức tạp của dữ liệu tài chính hiện đại.
Giải pháp Lưu trữ & Cơ sở Dữ liệu: Các nhà giao dịch định lượng cần các cơ sở dữ liệu có khả năng lưu trữ và truy vấn dữ liệu hiệu quả. Xử lý dữ liệu lớn trong SQL là một kỹ năng cơ bản khi làm việc với các cơ sở dữ liệu quan hệ, nhưng khi quy mô dữ liệu tăng lên, các giải pháp chuyên biệt như Kdb+ hay ClickHouse lại trở nên ưu việt hơn. Việc lựa chọn công cụ đúng sẽ tối ưu hóa hiệu suất làm việc và giảm thiểu thời gian chờ đợi.
Triển khai & Vận hành: Để quản lý các hệ thống phức tạp bao gồm thu thập dữ liệu, chạy mô hình và thực hiện giao dịch, các công cụ như Docker và Kubernetes giúp đóng gói và quản lý các ứng dụng một cách hiệu quả. Các nền tảng quản lý luồng công việc như Apache Airflow đảm bảo rằng toàn bộ quy trình dữ liệu được tự động hóa và chạy theo đúng lịch trình, giảm thiểu sai sót do con người.
Điện toán Đám mây & HPC: Các nhà giao dịch định lượng không nhất thiết phải đầu tư vào các trung tâm dữ liệu riêng. Các dịch vụ điện toán đám mây như AWS, GCP và Azure cung cấp một hạ tầng mạnh mẽ, linh hoạt và có khả năng mở rộng. Đặc biệt, việc sử dụng các cụm máy tính với GPU (HPC) trên đám mây đã giúp các quỹ giao dịch có thể chạy các mô hình học sâu phức tạp mà không cần phải đầu tư ban đầu quá lớn.
6. Quản trị Và Tuân thủ Quy định Về Xử lý Dữ liệu lớn
Cuối cùng, nhưng không kém phần quan trọng, là việc quản trị và tuân thủ các quy định.
Cấp phép Dữ liệu & Sở hữu Trí tuệ: Khi sử dụng các nguồn dữ liệu thay thế, việc đảm bảo tuân thủ các quy định về cấp phép dữ liệu là vô cùng quan trọng để tránh các rủi ro pháp lý.
Khả năng Kiểm toán: Toàn bộ quá trình từ thu thập, làm sạch đến mô hình hóa dữ liệu phải được ghi lại và theo dõi một cách có hệ thống. Điều này không chỉ giúp dễ dàng kiểm tra và khắc phục lỗi mà còn đáp ứng các yêu cầu kiểm toán và tuân thủ pháp luật.
Bảo mật & Quyền riêng tư: Việc bảo vệ dữ liệu nhạy cảm là một ưu tiên hàng đầu. Các hệ thống phải được trang bị các biện pháp bảo mật mạnh mẽ như mã hóa dữ liệu (encryption) và kiểm soát quyền truy cập chặt chẽ để bảo vệ thông tin khỏi các mối đe dọa.
Tuân thủ Pháp luật: Giao dịch định lượng phải tuân thủ nghiêm ngặt các quy định tài chính của các tổ chức như SEC (Ủy ban Chứng khoán và Giao dịch Hoa Kỳ) hay MiFID II (thị trường tài chính ở Liên minh châu Âu), đặc biệt là trong việc sử dụng và lưu trữ dữ liệu.
7. Từ lý thuyết đến thực chiến: Thử sức trên đấu trường XNO Quant
Nếu khai thác lợi nhuận từ chênh lệch giá là điều bạn quan tâm, thì đây là sân chơi để bạn trải nghiệm nó bằng cách tạo nên những robot giao dịch tự động và kiểm tra độ hiệu quả của chúng. Nếu trong quý đó bot của bạn trong top đem về lợi nhuận cao nhất, XNO sẽ có phần thưởng tương xứng. Ngoài ra, XNO Quant là cộng đồng tập hợp những nhà đầu tư định lượng tài năng, bạn có thể tạo mối quan hệ và học hỏi từ chiến lược giao dịch của họ. Hãy thể hiện bản lĩnh của bạn ngay hôm nay và xem nó có thể tiến xa đến mức nào nhé!
8. Thay vì làm một mình, hãy đồng hành cùng cộng đồng Quant & AI Việt Nam
Cộng đồng dành cho mọi nhà giao dịch và các bạn hứng thú với phương pháp giao dịch định lượng cũng như giao dịch tự động:Quant & AI Việt Nam - Đầu tư định lượng, sẽ hỗ trợ bạn với những kiến thức về đầu tư định lượng (từ thu thập dữ liệu đến xây dựng chiến lược giao dịch và giao dịch tự động). Hơn thế nữa, bạn sẽ là người truy cập sớm nhất thông tin về các buổi hội thảo offline với chuyên gia trong ngành, cũng như các cuộc thi về tài chính định lượng và dữ liệu do XNO tổ chức. Ngày bắt đầu tốt nhất chính là hôm nay, cộng đồng này đang chờ đón bạn.
Kết luận
Quá trình xử lý dữ liệu lớn trong giao dịch định lượng là một hệ sinh thái phức tạp, đòi hỏi sự kết hợp giữa kiến thức tài chính, kỹ năng lập trình và khả năng phân tích dữ liệu chuyên sâu. Từ việc lựa chọn nguồn dữ liệu phù hợp, xây dựng hạ tầng vững chắc, đến việc áp dụng các mô hình và công cụ hiện đại, mỗi bước đi đều là một thách thức lớn. Tuy nhiên, việc làm chủ quy trình này chính là chìa khóa để khai thác sức mạnh của dữ liệu, từ đó tạo ra những chiến lược giao dịch đột phá và mang lại lợi nhuận bền vững trên thị trường tài chính hiện đại.